Chapter 3 gave a brief introduction of the most frequently used options within \(\tau\)-Argus. In this section a more detailed description of the program by menu-item is presented. In Chapter 5 some general descriptions are given.
Compared with the previous versions of \(\tau\)-Argus (before 4.0 and before the Open Source version) the main window of \(\tau\)-Argus looks rather different. A window with the unsafe combinations by variable and by code was presented. This information however was seldom used and the main focus of the users of \(\tau\)-Argus was on the table itself. So from version 4.0 onwards the main window of \(\tau\)-Argus will show the table(s) itself.
4.1 Menu structure
There are five menu headings:
|
|
|
|
|
|
|
|
|
|
Below is a list of the menu items which are shown under each of themenu headings. As some of the items are context specific they will notall be always available. Overview of the menu-items
|
||||
|
|
|||
|
||||
The most important items of the menu can also be reached via thecorresponding icons:
|
|
||||||
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
||
These menu items will be explained in detail in the sections followingthe description of the main window. The Main window Starting with the Open Source version (4.0) the main window of \(\tau\)-Argushas been changed completely. In the previous versions an overview waspresented of the number of unsafe combinations for each explanatoryvariable and each code. However this information was hardy used andthe focus of the user is on the table(s) itself. So from now on thetable itself is the central point (the main window) of \(\tau\)-Argus. Assoon as the table has been completed, the table is presented here andthe process of disclosure control is controlled from this main window.
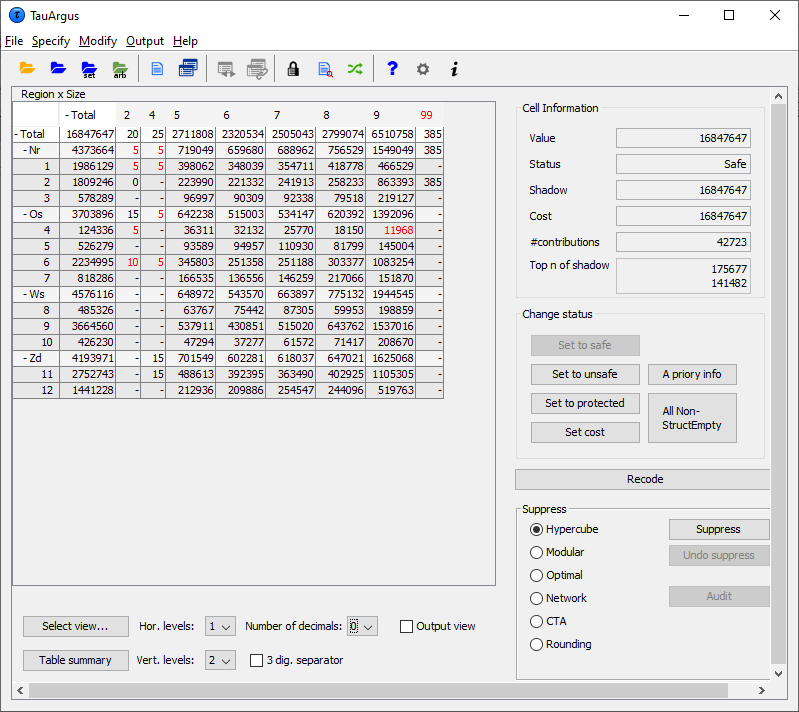
4.2 Viewing the table
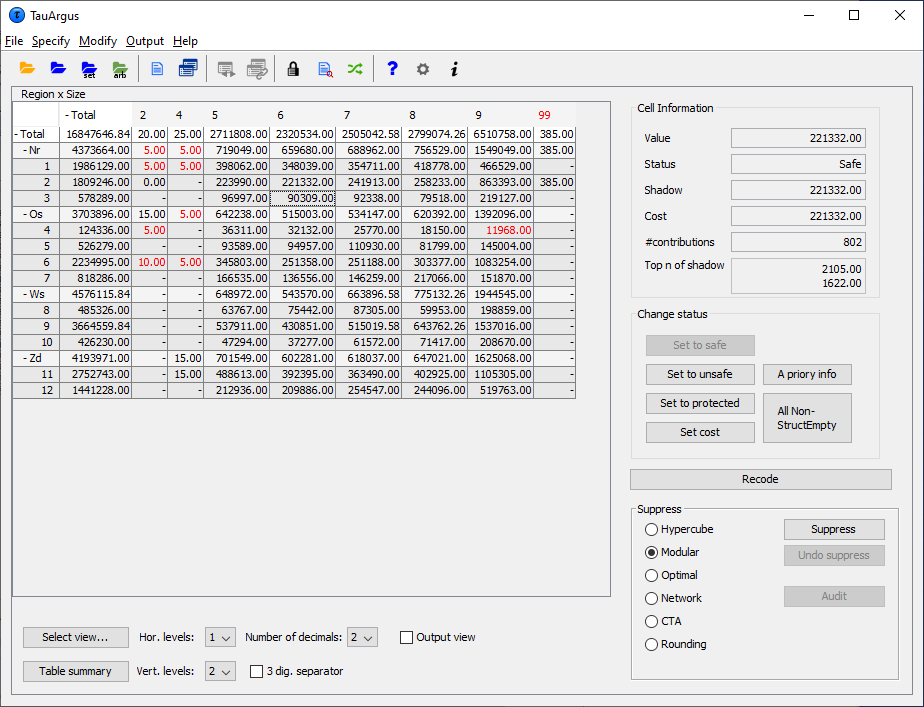
On the left side the table itself is shown in a spreadsheet view. Safecells are black, unsafe cells (those failing the primary suppressionrule) are red. In this example there are 12 unsafe cells and byviewing the table the user can now see the actual cells that areunsafe. Any secondary suppressed cells are shown in blue (there are none atthis stage, in this example) and empty cells have a hyphen (-). Thetwo check-boxes on the left-bottom give some control over the layout.
If the 3-digit separator box at the bottom is checked, the window > will show the cell-values, using the 3 digits separator to give a > more readable format.
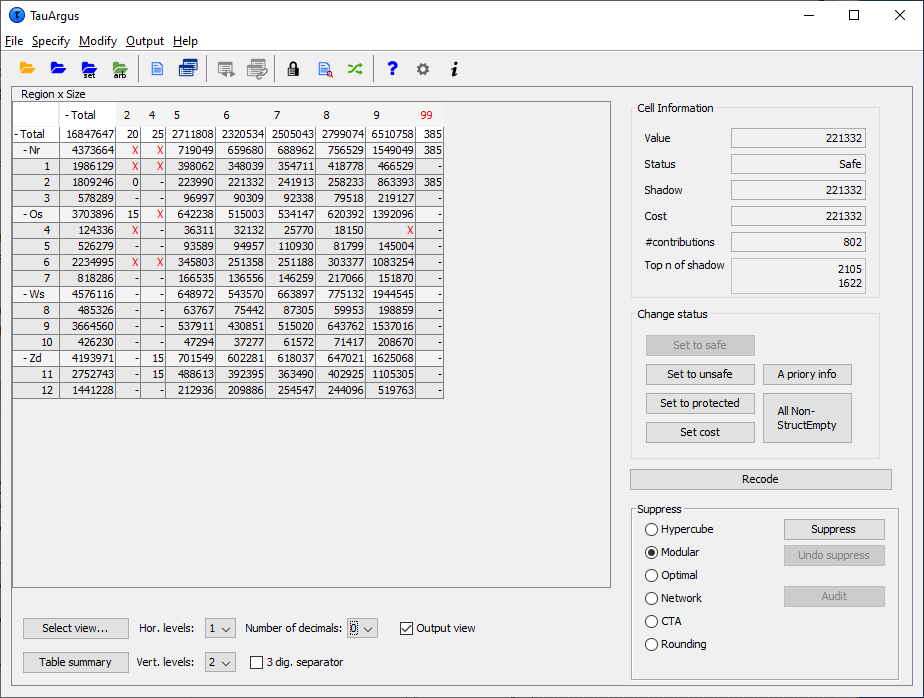
The Output view shows the table, with all the suppressed cells > replaced by an ‘X’; this is how the safe table will be published, > but without the colours distinguishing between primary and > secondary suppressions.
 For some windows, the complete table cannot be seen on the screen. Inthese cases there will be scrollbars at the bottom and the right ofthe table above, which can be used to display the unseen columns. For large tables one does not want to see the whole table on thescreen, which is virtually impossible. Therefore \(\tau\)-Argus will showonly the first two levels of the hierarchal structures. If you want tosee more you can open and close certain parts of the table by clickingon the codes with a ‘+’ or “-”sign. This works similar to the way youopen and close certain parts in the Windows explorer. Via ‘ChangeView’ at the bottom of the screen you can also select the level ofeach hierarchy you want to see both horizontally and vertically. Example of a 3-dimensional table 3-dimensional tables cannot be displayed as a whole. \(\tau\)-Argus can onlyshow a 2-dimensional layer of the table. So for higher dimensionaltable two variables are selected to be show. For the other variablescombo-boxes are shown. These combo-boxes allow for the selection of aspecific layer of the table. Just select the corresponding code andthat layer will be shown. If you want to see another combination of two explanatory variables,go to “Select view” at the bottom of the window. See section[4.2.7].
For some windows, the complete table cannot be seen on the screen. Inthese cases there will be scrollbars at the bottom and the right ofthe table above, which can be used to display the unseen columns. For large tables one does not want to see the whole table on thescreen, which is virtually impossible. Therefore \(\tau\)-Argus will showonly the first two levels of the hierarchal structures. If you want tosee more you can open and close certain parts of the table by clickingon the codes with a ‘+’ or “-”sign. This works similar to the way youopen and close certain parts in the Windows explorer. Via ‘ChangeView’ at the bottom of the screen you can also select the level ofeach hierarchy you want to see both horizontally and vertically. Example of a 3-dimensional table 3-dimensional tables cannot be displayed as a whole. \(\tau\)-Argus can onlyshow a 2-dimensional layer of the table. So for higher dimensionaltable two variables are selected to be show. For the other variablescombo-boxes are shown. These combo-boxes allow for the selection of aspecific layer of the table. Just select the corresponding code andthat layer will be shown. If you want to see another combination of two explanatory variables,go to “Select view” at the bottom of the window. See section[4.2.7]. 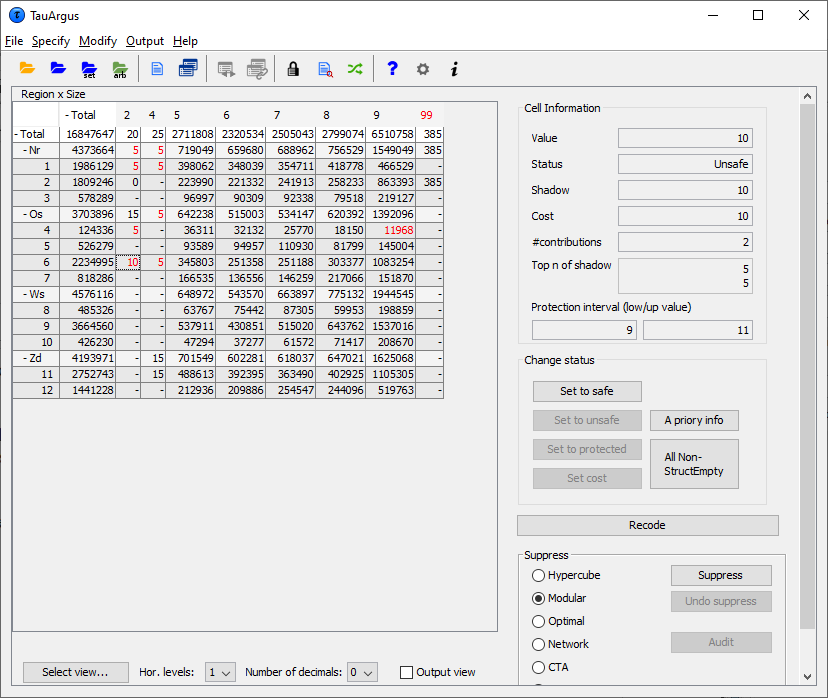 ****Additional information in the View Table window**** Clicking on a cell in the main body of the table makes informationabout this cell visible in the Cell Information**** pane****.**** Here, the following information can be seen:
****Additional information in the View Table window**** Clicking on a cell in the main body of the table makes informationabout this cell visible in the Cell Information**** pane****.**** Here, the following information can be seen:

the cell-value
the cell status
the value of cost variable
the value of the shadow variables
the number of contributors
the values of the largest contributors of the shadow variable ****In addition for a primary unsafe cell also the required lower andupper protection levels are shown. If you put your mouse over thisvalue, also the lower and upper protection as a distance to the cellvalue is shown together with the same value as a percentage. **** Information about the Holding level and the Request protectionvariable are also displayed here. The status of the cell can be:
Safe: Does not violate the safety rule
Safe (from manual): manually made safe during this session
Unsafe: According to the safety rule
Unsafe (request): Unsafe according to the Request rule.
Unsafe (frequency): Unsafe according to the minimum frequency rule.
Unsafe (from manual): manually made unsafe during this session (see > ‘Change Status’ below).
Protected: Cannot be selected as a candidate for secondary cell > suppression (see ‘Change Status’ below).
Secondary: Cell selected for secondary suppression.
Secondary (from manual): Unsafe due to secondary suppression after > primary suppressions carried out manually (see ‘Change Status’ and > ‘Secondary suppressions’ below).
Empty: No records contributed to this cell and the cell cannot be > suppressed. Change Status The second pane (‘Change Status’) on the right will allow the user tochange the cell–status.
Set to Safe: A cell, which was unsafe, e.g. due to the safety rules > is made safe by the user.
Set to Unsafe: A cell, which has passed the safety rules is made > unsafe by the user. Hence the manual safety margin is applied
Set to Protected: A safe cell is set so that it cannot be selected > for secondary suppression. Note: use this option with care as > the result might be that no solution can be found. Alternatively > consider to set the cost-variable to a very high value.
Set Cost: Change the cost function for a cell.
4.2.1 A priori info
This option allows you to feed \(\tau\)-Argus a list of cells where thestatus of the standard rules can be overruled. E.g. a cell must bekept confidential or not for other reasons that just because of thesensitivity rules. By modifying the cost-function you can influencethe selection of the secondaries. E.g. the cells suppressed last yearcan get a preference for the suppression this year by giving this cella small value for the cost-function. The option ‘Expand trivial levels’ is important. Often in a table withhierarchies, some levels in a hierarchy break down in only one lowerlevel. This implies that there are different cells in a table whichare implicitly the same. Changing the status of one of them might leadto inconsistencies and serious problems. E.g. one if the two is unsafeand the other is protected, the solution is impossible. If you selectthe option ‘Expand trivial levels’, τ‑argus will always modify allcells that are the same if you modify one of them. The format of the file is free format. The separator can be chosen. The format is: Code of first spanning variable, Code of second spanning variable,…,Status of cell (u = unsafe, p = protected (not to be suppressed), s =safe). Also the cost-function can be changed here for a cell. This will makethe cell more likely to become secondary cell suppression, when thevalue is low, or less likely when the value is high. Normally the sensitivity rules will also give the required protectionlevels for unsafe cells. But sometimes, e.g. in the case of ‘manualunsafe cells’ the user might want to specify the required protectionlevel different for a standard percentage. After the keyword ‘pl’, thelower and upper protection levels can be given for a specific cell.Note that the protection levels will always have to be positive, asthey are considered as distances from the cell-value. A full description of the apriori file is given in section[5.6]. Nr, 4, u Zd, 6, p 5, 5, c, 1 Zd, 5, pl, 100, 200 When the apriori file has been applied \(\tau\)-Argus will show an overviewof the changes that have been made to the table. 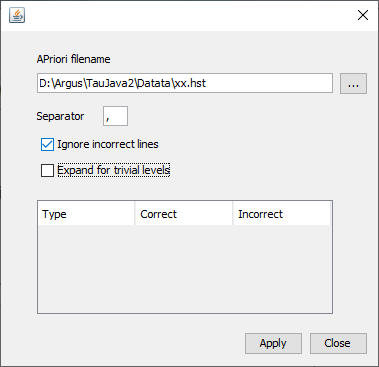
4.2.2 Global recoding
The recode button will open the recoding options. Recoding is a verypowerful method of protecting a table. Collapsed cells tend to havemore contributors and therefore tend to be much safer. Recoding a variable always starts with the original codes. It is notpossible to refine a recoding. If required you must start with acomplete new recoding. ****Recoding a non-hierarchical variable**** There is a clear difference in recoding a hierarchical variablecompared to a non-hierarchical variable. In the non-hierarchical case the user can specify a global recodingmanually. Either enter the recoding described below manually or readit from a file. The default extension for this file is .GRC. Detailscan also be found in section [5.4]. 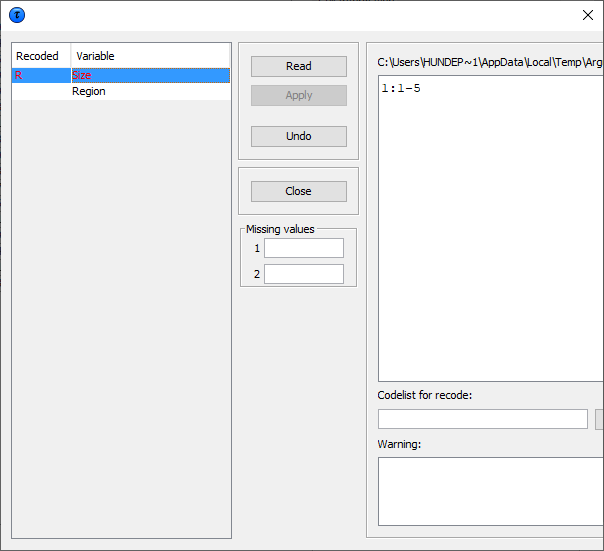 There are some standards about how to specify a recode scheme. Always the new code is specified first followed by a colon (`:`).After that the set of old codes to be collapsed into the new code isspecified. All codelists are treated as alphanumeric codes. This means thatcodelists are not restricted to numerical codes only. However, thisalso implies that the codes '01' and ' 1' are considered differentcodes and also 'aaa' and 'AAA' are different. In a recoding schemethe user can specify individual codes separated by a comma (,) orranges of codes separated by a hyphen (-). The range is determined bytreating the codes as strings and using the standard stringcomparison. E.g. `0111`< `11` as the `0` precedes the `1` and`ZZ’< `a` as the uppercase `Z` precedes the lowercase `a`.Special attention should be paid when a range is given without a leftor right value. This means every code less or greater than the givencode. In the first example, the new category 1 will contain all thecodes less than or equal to 49 and code 4 will contain everythinglarger than or equal to 150. Example:a variable with the categories 1,…,182 a possible recode isthen: 1: - 49 2: 50 - 99 3: 100 – 149 4: 150 – for a variable with the categories 01 till 10 a possible recode is: 1: 01 , 02 2: 03 , 04 3: 05 – 07 4: 08 , 09 , 10 An important point is not to forget the colon (:) if it is forgotten,the recode will not work.: 05,06,07 can be shortened to 3: 05-07. Additionally, changing the coding for the missing values can beperformed by entering these codes in the relevant textboxes. Also a new codelist with the labels for the new coding scheme can bespecified. This is entered by means of a codelist file. An example isshown here. (note, there are no colons is this file) 1,Groningen 2,Friesland 3,Drenthe 4,Overijssel 5,Flevoland 6,Gelderland 7,Utrecht 8,Noord-Holland 9,Zuid-Holland 10,Zeeland 11,Noord-Brabant 12,Limburg Nr,North Os,East Ws,West Zd,South Pressing the ‘Apply’ button will actually restructure the table. Thevariable concerned will be displayed in red and additionally an x isshown in front of the variable. If required, recoding can easily beundone by pressing 'undo recoding'. The window will return to theoriginally coding structure. If there is any error in the recodingsuch as certain codes not being found when pressing the ‘Apply’button, an error message will be shown at the bottom of the screen.Alternatively, a warning could be issued; e.g. if the user did notrecode all original codes, \(\tau\)-Argus will inform the user. This may havebeen the intention of the user, therefore the program allows it. Inthe above example a \(\tau\)-Argus message informs the user that 4 codes havenot been changed. At the end of the operation τ‑argus will ask you whether or not amodified recoding scheme must be saved or not.
There are some standards about how to specify a recode scheme. Always the new code is specified first followed by a colon (`:`).After that the set of old codes to be collapsed into the new code isspecified. All codelists are treated as alphanumeric codes. This means thatcodelists are not restricted to numerical codes only. However, thisalso implies that the codes '01' and ' 1' are considered differentcodes and also 'aaa' and 'AAA' are different. In a recoding schemethe user can specify individual codes separated by a comma (,) orranges of codes separated by a hyphen (-). The range is determined bytreating the codes as strings and using the standard stringcomparison. E.g. `0111`< `11` as the `0` precedes the `1` and`ZZ’< `a` as the uppercase `Z` precedes the lowercase `a`.Special attention should be paid when a range is given without a leftor right value. This means every code less or greater than the givencode. In the first example, the new category 1 will contain all thecodes less than or equal to 49 and code 4 will contain everythinglarger than or equal to 150. Example:a variable with the categories 1,…,182 a possible recode isthen: 1: - 49 2: 50 - 99 3: 100 – 149 4: 150 – for a variable with the categories 01 till 10 a possible recode is: 1: 01 , 02 2: 03 , 04 3: 05 – 07 4: 08 , 09 , 10 An important point is not to forget the colon (:) if it is forgotten,the recode will not work.: 05,06,07 can be shortened to 3: 05-07. Additionally, changing the coding for the missing values can beperformed by entering these codes in the relevant textboxes. Also a new codelist with the labels for the new coding scheme can bespecified. This is entered by means of a codelist file. An example isshown here. (note, there are no colons is this file) 1,Groningen 2,Friesland 3,Drenthe 4,Overijssel 5,Flevoland 6,Gelderland 7,Utrecht 8,Noord-Holland 9,Zuid-Holland 10,Zeeland 11,Noord-Brabant 12,Limburg Nr,North Os,East Ws,West Zd,South Pressing the ‘Apply’ button will actually restructure the table. Thevariable concerned will be displayed in red and additionally an x isshown in front of the variable. If required, recoding can easily beundone by pressing 'undo recoding'. The window will return to theoriginally coding structure. If there is any error in the recodingsuch as certain codes not being found when pressing the ‘Apply’button, an error message will be shown at the bottom of the screen.Alternatively, a warning could be issued; e.g. if the user did notrecode all original codes, \(\tau\)-Argus will inform the user. This may havebeen the intention of the user, therefore the program allows it. Inthe above example a \(\tau\)-Argus message informs the user that 4 codes havenot been changed. At the end of the operation τ‑argus will ask you whether or not amodified recoding scheme must be saved or not. 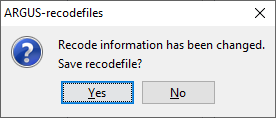 Once the ’Close’ button has been pressed, \(\tau\)-Argus will present thetable with the recoding applied. Recoding a hierarchical variable
Once the ’Close’ button has been pressed, \(\tau\)-Argus will present thetable with the recoding applied. Recoding a hierarchical variable 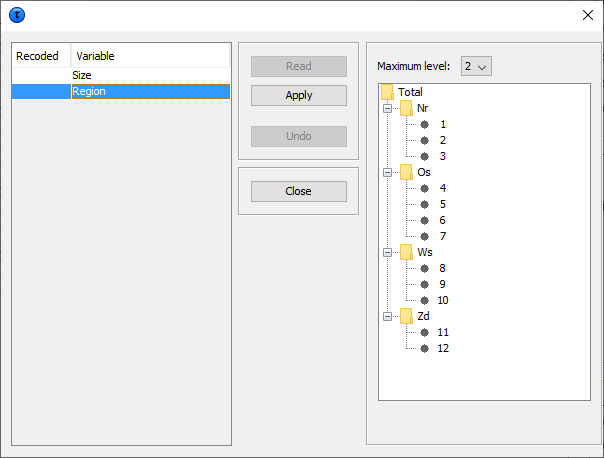 In the hierarchical case the code scheme is typically a tree. Toglobal recode a hierarchical variable requires a user to manipulate atree structure. The standard Windows tree view is used to present ahierarchical code. Certain parts of a tree can be folded and unfoldedwith the standard Windows actions (clicking on ‘+’ and ‘-’). The maximum level box at the top of the screen offers the opportunityto fold and unfold the tree to a certain level. Pressing the ‘Apply’ button will actually restructure the table. Ifrequired, a recoding may always be undone.
In the hierarchical case the code scheme is typically a tree. Toglobal recode a hierarchical variable requires a user to manipulate atree structure. The standard Windows tree view is used to present ahierarchical code. Certain parts of a tree can be folded and unfoldedwith the standard Windows actions (clicking on ‘+’ and ‘-’). The maximum level box at the top of the screen offers the opportunityto fold and unfold the tree to a certain level. Pressing the ‘Apply’ button will actually restructure the table. Ifrequired, a recoding may always be undone.
4.2.3 Secondary suppression
When the table is ready, the most commonly used method to protect atable is secondary cell suppression With suppress the table will be protected by causing additional cellsto be suppressed. This is necessary to make a safe table. Suppression Options There are a number of suppression options, which can be seen on thebottom right hand side of the window.
Hypercube
Modular
Optimal
Network
4.2.3.1 Hypercube
This is also known as the ghmiter method. The approach builds on thefact that a suppressed cell in a simple n‑dimensional table withoutsubstructure cannot be disclosed exactly if that cell is contained ina pattern of suppressed, nonzero cells, forming the corner points of ahypercube. Selecting the hypercube method will lead to the followingwindow being showed by \(\tau\)-Argus. ghmiter will select secondary suppressions that protect the sensitivecells properly against the risk of inferential disclosure, to someextent, if the user activates the option “Protection againstinferential disclosure required”. If the option is inactivated, onthe other hand, ghmiter will not check secondary suppressions to besufficiently large. For more explanation, and detailed information on the hypercube seesection [2.8]. The lower part of the window above enables the user to affect thesetting of two parameters, “Max sub-codelist size” and “Max sub-tablesize” that GHMITER uses for memory allocation. If the option ‘normal size’ is active, the default values mentionedbelow will be used. Ticking the option ‘large size’ will lead to asetting of 250 and 25000, respectively. “Max sub-codelist size” must exceed the largest maximum sub-codelistsize of all explanatory variables of the table. The maximumsub-codelist size of a (hierarchical) variable is the largest numberof categories on the same (hierarchical) level that contribute to thesame category on the (hierarchical) level just above. The defaultvalue for “Max sub codelist size” is 200. “Max sub-table size” must exceed the number of cells in the largestsubtable, e.g. the product of the maximum sub-codelist sizes takenover all explanatory variables. The default value is 6000. Note that we strongly recommend designing tables so that they fit the’normal’ setting, e.g. better think about restructuring the tablerather than using the ‘large’ option. The better approach (instead ofusing the ‘large’ option) would be to introduce a (more detailed)hierarchical structure into the table, because in this way the tablewill provide more information to the user. The Cancel button will bring you back to the main window, withoutprotecting the table.
4.2.3.2 Modular
This partial method will break down the hierarchical table intoseveral non-hierarchical tables, protect them and compose a protectedtable from the smaller tables. As this method uses the optimisationroutines, an LP-solver is required: this can be either Xpress or cplexor a free solver. The routine used can be specified in the Optionsbox, this will be discussed later. After starting the modular procedure a little window will be shown.This allows to select three additional rules to be applied. At the endof section [2.10] more information on these three rulescan be found. 
4.2.3.3 Optimal
This method protects the (hierarchical) table as a single tablewithout breaking it down into smaller tables. As this method uses theoptimisation routines, an LP-solver is required: this can be eitherXpress or cplex or a free solver. The routine used can be specified inthe Options box, this will be discussed later. It is the responsibility of the users of \(\tau\)-Argus to apply for alicence for one of these commercial packages themselves. Informationon obtaining one of these licences will be found in a ‘read.me’ filesupplied with the software or on the CASC website. Almost the same window as in Modular is shown to select the 3additional rules; see above. 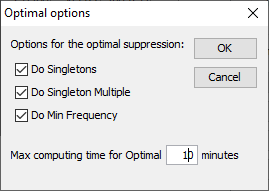 But a further question is asked. The question is ‘How much time do youallow the system to compute the optimal solution’. When the specified time limit has been reached τ‑argus will ask youwhat to do. This can be twofold, you allow τ‑argus to continue for anew amount of time, or not. The window below allows you to specifythis. Note that τ‑argus will check only at a specific location in a cyclewhether or not the time has elapsed.
But a further question is asked. The question is ‘How much time do youallow the system to compute the optimal solution’. When the specified time limit has been reached τ‑argus will ask youwhat to do. This can be twofold, you allow τ‑argus to continue for anew amount of time, or not. The window below allows you to specifythis. Note that τ‑argus will check only at a specific location in a cyclewhether or not the time has elapsed. 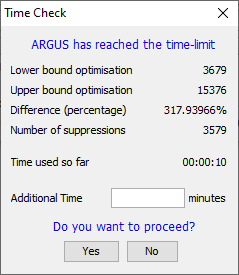
4.2.3.4 Network
This is a Network Flow approach for large unstructured 2 dimensionaltables with only one hierarchy (the first variable specified). Theuser has the option of selecting an optimisation method (pprn andDykstra). Both optimisation methods are available free of anadditional licence. By default the Dykstra solution is advised. 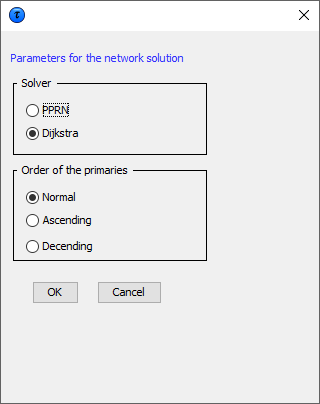 As the network solution is a heuristic to find an approximation of thereal optimal solution, it cannot be expected that always an optimalsolution is found. Nevertheless it is guaranteed that at least a goodfeasible solution is found in a relatively short time. The order inwhich the primaries are provided to the network algorithm couldinfluence the solution found. Therefore three options are available toorder the primaries.
As the network solution is a heuristic to find an approximation of thereal optimal solution, it cannot be expected that always an optimalsolution is found. Nevertheless it is guaranteed that at least a goodfeasible solution is found in a relatively short time. The order inwhich the primaries are provided to the network algorithm couldinfluence the solution found. Therefore three options are available toorder the primaries.
4.2.3.5 After the suppression
After selecting one of the options and after clicking the Suppressbutton, \(\tau\)-Argus will run and display a protected table after informingthe user of the number of cells selected for secondary suppression andthe time taken to perform the operation. 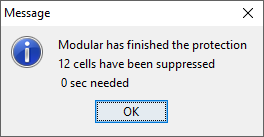 The secondary suppressed cells will be shown in blue.
The secondary suppressed cells will be shown in blue. 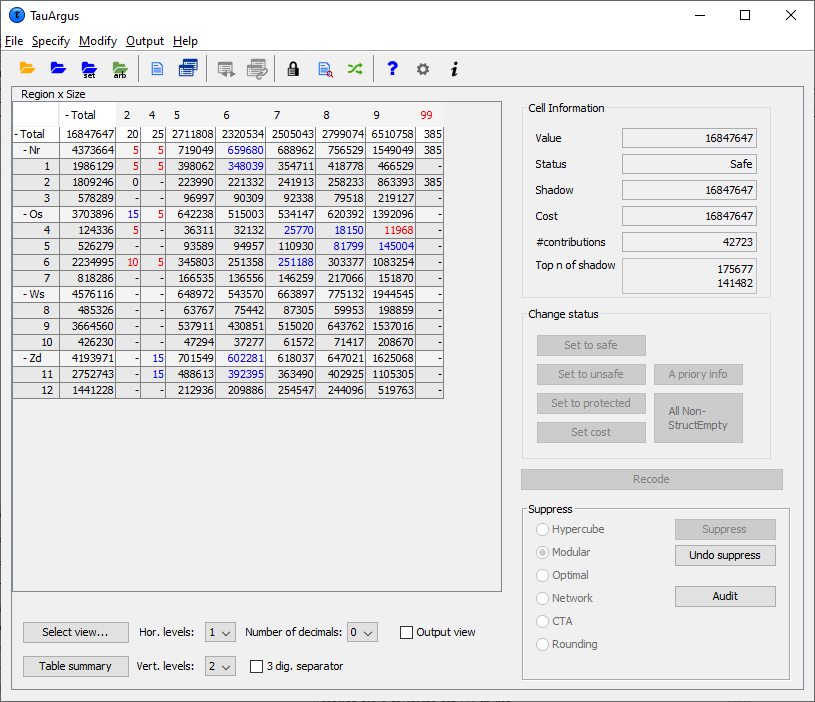 When the user is satisfied with the table it can be saved (see section[4.6.1] for the possible formats). Via the menuOutput|Save table you can specify the format and start the process ofsaving a table.
When the user is satisfied with the table it can be saved (see section[4.6.1] for the possible formats). Via the menuOutput|Save table you can specify the format and start the process ofsaving a table.
4.2.4 Controlled Tabular Adjustment
A method new in version 4.0 of \(\tau\)-Argus is a method called ControlledTabular Adjustment. Instead of suppressing a set of cells, a selectedset of cells is modified. The aim is to change the sensitive cellssuch that the cells are replaced by a value larger that the upperprotection level or smaller than the lower protection level. i.e. farenough away from the unsafe value.. And a set of safe cells ismodified such that the resulting table is additive again. Of course wetry to minimise the information loss. More information can be found in section [2.13]. We have implemented two variants. A standard version, suitable forgeneral cases, and an expert version for the specialists. 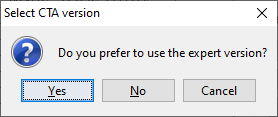 The standard version will run CTA without any further questions. The expert version will show the following window: You can e.g. selectthe solver and the type of CTA. We further refer to the detailed CTAdocumentation.
The standard version will run CTA without any further questions. The expert version will show the following window: You can e.g. selectthe solver and the type of CTA. We further refer to the detailed CTAdocumentation. 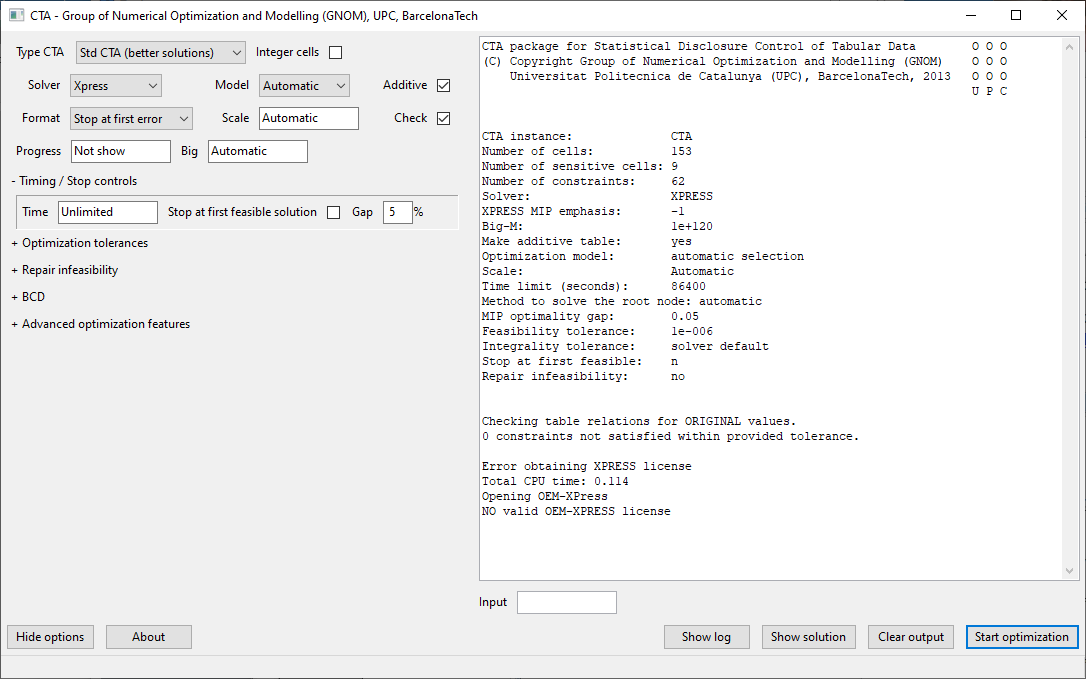
4.2.5 Controlled rounding
Controlled rounding (see Section [2.14] for details onthis method) requires a solver that allows you using the Mixed IntegerModel (MIP). Already in version 3 of τ‑argus we had access to MIP inXpress, thanks to the friendly cooperation of Dash Inc and later FICO.However the restricted version of the cplex licence we used in version3 of \(\tau\)-Argus did not have access to MIP. But from now on you can buy alicence for cplex including MIP. This allows you to use ControlledRounding with a new cplex licence. Also the free solver, soplex, can be used for Controlled Rounding. In general, rounding is more appropriate for frequency tables than formagnitude tables. The next figure shows the simple frequency table obtained from thetest data using the variable Size and Region. 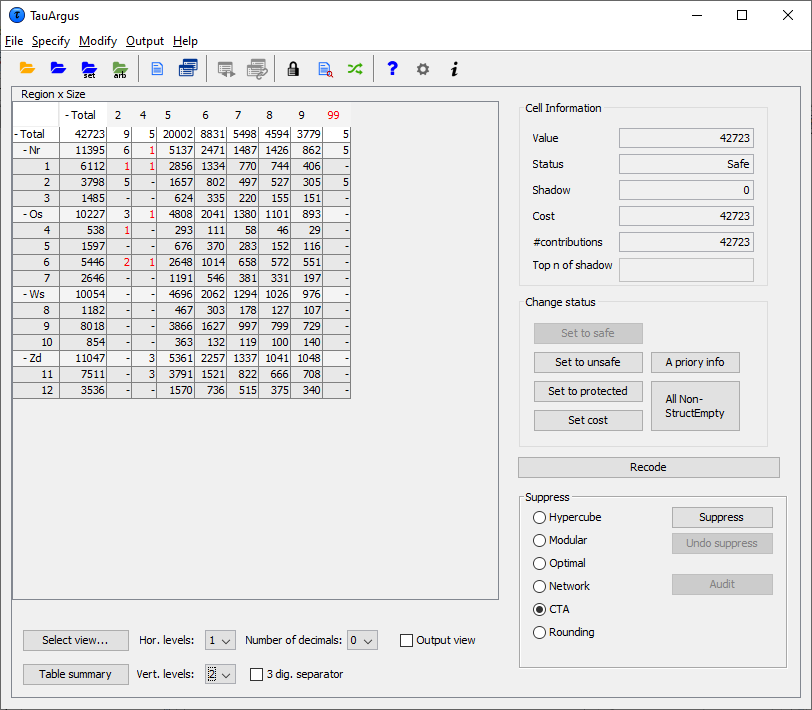 Rounding can be applied also to tables with no unsafe cells. Thechoice of the minimum threshold and whether zeros are safe or not hasan effect on the minimal possible rounding base, as it will beexplained in the Option paragraph. When rounding has been chosen and the round-button has been pressed,the following window will be shown. You can enter a few parameters. Rounding Options
Rounding can be applied also to tables with no unsafe cells. Thechoice of the minimum threshold and whether zeros are safe or not hasan effect on the minimal possible rounding base, as it will beexplained in the Option paragraph. When rounding has been chosen and the round-button has been pressed,the following window will be shown. You can enter a few parameters. Rounding Options 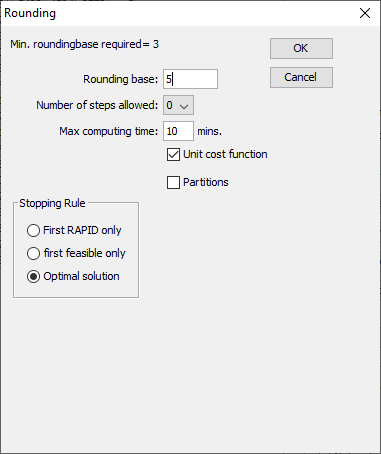 The controlled rounding window allows to set the following parameters:
The controlled rounding window allows to set the following parameters:
Rounding Base
> Cell values will be changed to multiples of the base. The minimum > rounding base is equal to the maximum between the minimum > frequency threshold and twice the highest Protection Level set for > an unsafe cell (with the Dominance or p-q rule). See the Section > [2.2] for details on safety rules and section > [2.6] protection levels. If no rule is specified the > minimum base is 1. Rounding can be used to round a table for > “cosmetic” motives.Number of steps allowed
> This value specifies the maximum number of steps allowed in > order to find a feasible solution when a zero-restricted one does > not exist. The default value is 0, i.e. zero-restricted. Higher > values can be chosen by selecting the value from the drop-down > menu. Note that the higher the number of steps allowed the > lengthier is the search, hence the greater the risk of hitting the > time constraint. At any rate, if a zero-restricted solution > exists, this is the solution provided, whatever the number of > steps allowed.Max computing time
> This value determines the time after which the user is prompted > for a decision about continuing or stopping the search. The > default value is 20 minutes. When the maximum time is hit the user > is prompted to enter a new maximum time or to choose to terminate > the search.Partitions
> This option enables the partitioning of the table into sub-tables > corresponding to each category of the first spanning variable. > This option is recommended for tables with more than approximately > 150,000 cells. Partitioning can only be used in this version when > the first variable is non-hierarchical. The first variable should > be such that the sub-tables have maximum size of about 150,000 > cells and also trying to keep their number low; performance may be > improved by wisely choosing the partitioning variable. See Section > (rounding theory) for further details.Stopping Rule These options allow to control the quality of the rounded solution.The user can choose:
First Rapid
> The solution is obtained by rounding conventionally (to the > closest multiple of the base) the internal cells and then the > marginal values are obtained by addition. This solution is likely > to present several values that have a large distance from the > original values. This option should be used with extreme care and, > likely, when everything else fails;First feasible
> The solution provided is the first rounded one that has the > specified number of jumps, regardless of its optimality. This > means that there could exist other solutions that have a lower > overall distance from the original table. In many cases, when > optimality is not crucial, this solution is quite close to the > optimal one and it can be found in a shorter time;Optimal
> This option provides the fully optimal controlled rounded > solution.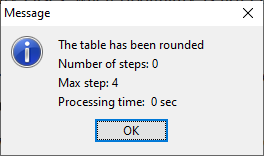 The rounded table The next figure shows the rounded table with the values rounded tomultiples of 5. Note that the values that were originally zero (henceempty cells denoted with a dash) are still shown as a dash while thevalues that have been rounded down to zero are shown as zeros.
The rounded table The next figure shows the rounded table with the values rounded tomultiples of 5. Note that the values that were originally zero (henceempty cells denoted with a dash) are still shown as a dash while thevalues that have been rounded down to zero are shown as zeros. 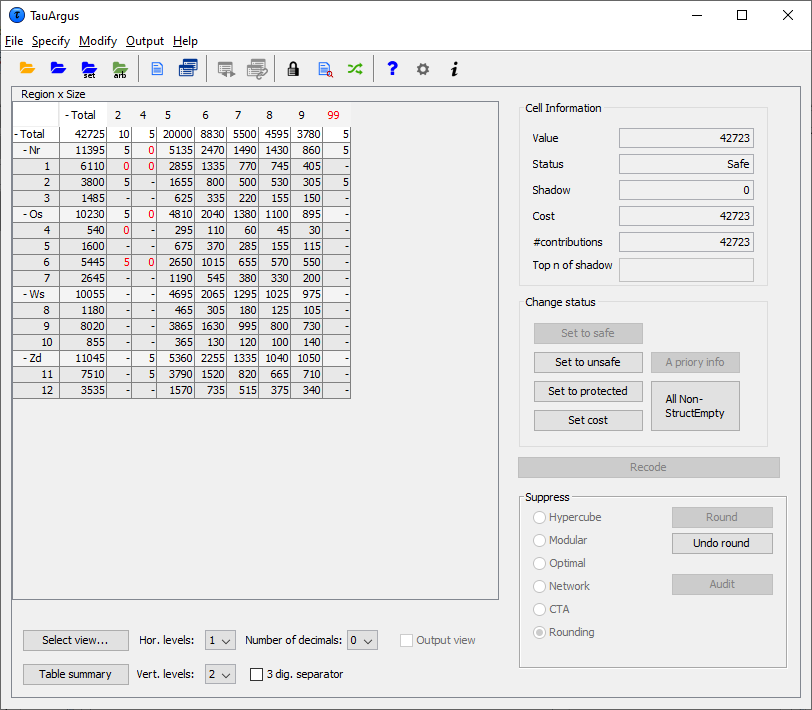
4.2.6 The audit procedure
After the secondary cell suppression procedure has been carried outall cells should have been properly protected. Cell suppressionguarantees that unsafe cells cannot be estimated to a narrowerinterval that the required protection interval. The realised upper andlower bounds can be computed by solving two linear programmingproblems for each unsafe cell. This can be rather an effort doing itall manually, but the audit procedure will do this. Note that theModel solved by the audit procedure will check only for the requiredprotection levels, but not for the additional singleton protection.See also section [2.15]. The Audit option will only be active after secondary cell suppression.By activating the procedure all the linear programming problems forall unsafe (both primary and secondary) cell will be computed. Whencompleted a message will be showing whether all cells were protectedcorrectly. 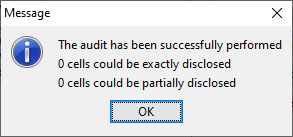 If in the unfortunate case the protection was not optimal according tothe audit procedure a list of problems will be shown. Also theproblematic cells will be highlighted. For each unsafe cell the realised lower and upper bounds will beshown. If you put your mouse on the value also the distance to thereal value and the corresponding percentage will be shown
If in the unfortunate case the protection was not optimal according tothe audit procedure a list of problems will be shown. Also theproblematic cells will be highlighted. For each unsafe cell the realised lower and upper bounds will beshown. If you put your mouse on the value also the distance to thereal value and the corresponding percentage will be shown 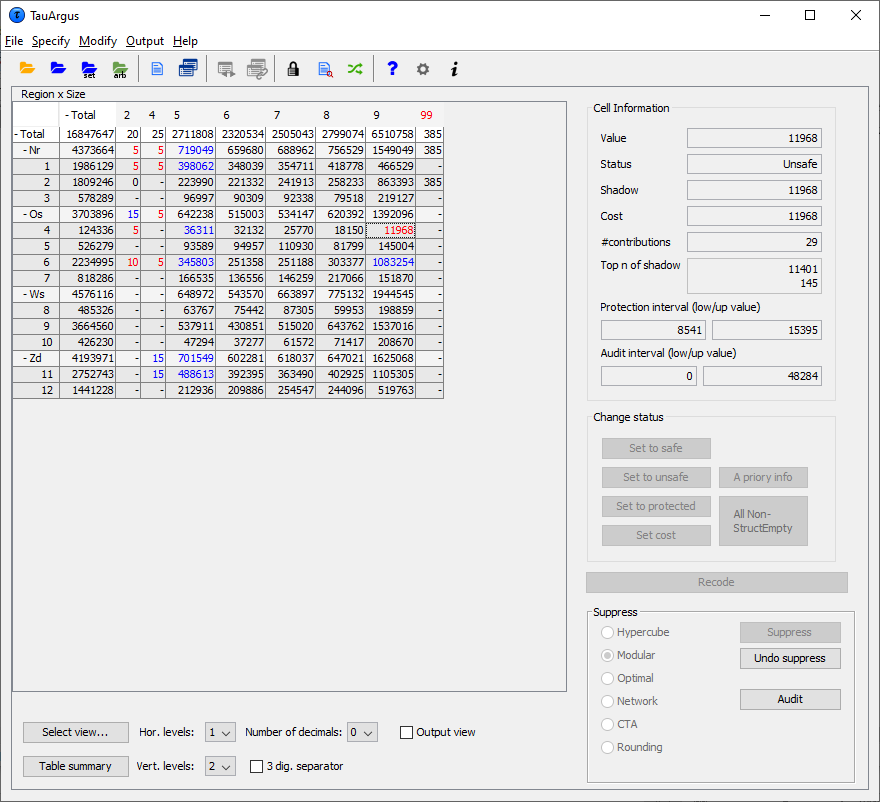
4.2.7 The Options at the Bottom of the table
At the bottom of this window there are a few additional options. Theseoptions will be described here. Select View By clicking on Select View a dialog box below pops up. The user canspecify which variable is preferred in the row and the column. In thetwo-dimensional case, the table can only be transposed. In the higherdimensional case, the remaining variables will be in the layer. Forthese layer variables a combo-box will appear at the top of the table,where the user can select a code. This will show the correspondingslice of the table. 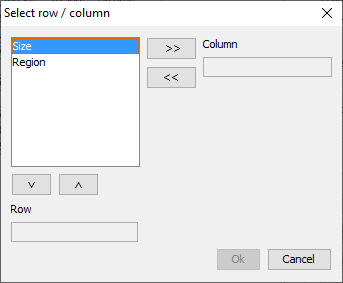 For a 3 dimensional table, this window is as follows:
For a 3 dimensional table, this window is as follows: 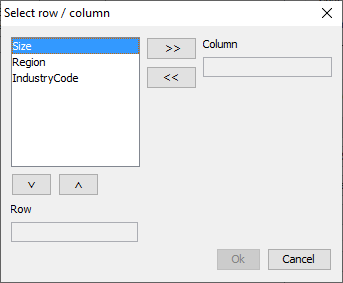 Table summary Pressing 'table summary' provides a table summary giving an overviewof the number of cells according to their status. The example shownhere refers to the case after secondary suppression has beenperformed.
Table summary Pressing 'table summary' provides a table summary giving an overviewof the number of cells according to their status. The example shownhere refers to the case after secondary suppression has beenperformed. 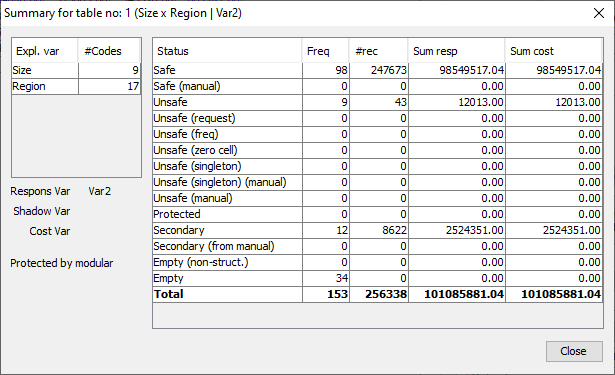 The headings in the summary window are as follows: Freq: The number of cells in each category # rec: The number of observations in each category Sum resp: Total cell value in each category Sum cost: The sum of the cost variable. Hor. Levels and Vert. levels A large (hierarchical) table can never be showncompletely on the screen. Therefor \(\tau\)-Argus will start by showing onlythe top-2 levels of the hierarchy. With these options you can specifythat more levels of the table must be shown. Alternatively you can click on the + and – symbols ofthe hierarchical codes in the table to fold and unfold parts of thetable. ****3 dig separator**** This removes or inserts the character separating the thousands for thevalues in the table. Output View This option allows the table to be shown as it will be output, withsuppressed cells (primary and secondary) replaced by a X.
The headings in the summary window are as follows: Freq: The number of cells in each category # rec: The number of observations in each category Sum resp: Total cell value in each category Sum cost: The sum of the cost variable. Hor. Levels and Vert. levels A large (hierarchical) table can never be showncompletely on the screen. Therefor \(\tau\)-Argus will start by showing onlythe top-2 levels of the hierarchy. With these options you can specifythat more levels of the table must be shown. Alternatively you can click on the + and – symbols ofthe hierarchical codes in the table to fold and unfold parts of thetable. ****3 dig separator**** This removes or inserts the character separating the thousands for thevalues in the table. Output View This option allows the table to be shown as it will be output, withsuppressed cells (primary and secondary) replaced by a X.
4.3 The File menu
\(\tau\)-Argus can read data in two ways. The first option is that \(\tau\)-Arguswill read the data from a microdata file (fixed format, free formatand a SPSS_systemfile), which is explained in Section 4.3.1. From this microdata \(\tau\)-Argus can then build oneor more tables and during this tabulation process compute allnecessary additional information, needed to fully protect a table.This is the most flexible way allowing using all the functionality of\(\tau\)-Argus. The second option is the input and treatment of a pre-tabulated dataand is dealt with in section [4.3.2]. Only one of theseoptions can be used at one time, a pre-tabulated table and tablescomputed from microdata cannot be read in \(\tau\)-Argus simultaneously. A set of pre-tabulated tables can be read into \(\tau\)-Argus and via thelinked tables procedure be protected. See section[4.3.3]. \(\tau\)-Argus can also be used in batch, see section [4.3.4]. Finally the \(\tau\)-Argus can be closed.
4.3.1 File | Open Microdata
The File|Open microdata menu allows the user to specify the microdatafile (both fixed and free format or a SPSS-system file) and optionallythe metadata file. Note that a valid licence for SPSS must be available on your PC, atτ‑argus will use the functionality of SPSS to extract the microdatafrom SPSS to a scratch file. This file will then be used to constructthe tables to be protected. 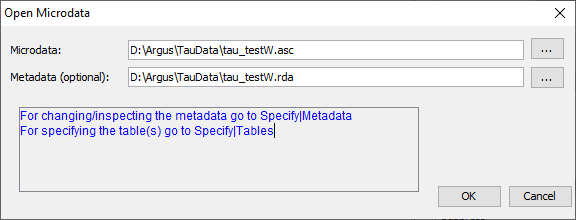 In this dialog box the user can select the microdata-file or the SPSSsystem file and optionally the corresponding metadata file By default the microdata-file has extension .asc and the metafile.rda. .(Note, the user may use any file extension, but is advised touse default names).
In this dialog box the user can select the microdata-file or the SPSSsystem file and optionally the corresponding metadata file By default the microdata-file has extension .asc and the metafile.rda. .(Note, the user may use any file extension, but is advised touse default names).  When the user clicks on he will get the traditionalopen file dialog box.
When the user clicks on he will get the traditionalopen file dialog box. 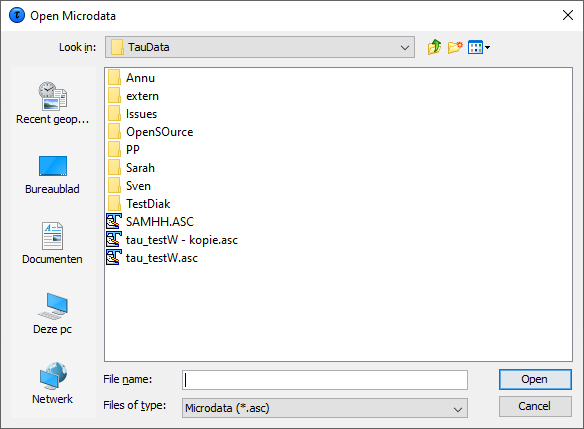 This box enables searching for the required files. Otherfile-extensions can be chosen when clicking on the files of typelistbox. When the user has selected the microdata file a suggestionfor the metafile (with the same name but with the extension .rda) isgiven but only when this file exists. Note, both files do notnecessarily have to have the same name. If a user selects a data file with another extension,\(\tau\)-Argus willremember this and will suggest this extension in a future use of\(\tau\)-Argus. A full description of the metadata file can be found in section[5.1]. When the data file has been selected and optionally the meta datafile, you can proceed to the menu options Specify|Metafile toedit/modify the meta data file and to Specify|Tables to specify thetables required. See section [4.4] and[4.4.4].
This box enables searching for the required files. Otherfile-extensions can be chosen when clicking on the files of typelistbox. When the user has selected the microdata file a suggestionfor the metafile (with the same name but with the extension .rda) isgiven but only when this file exists. Note, both files do notnecessarily have to have the same name. If a user selects a data file with another extension,\(\tau\)-Argus willremember this and will suggest this extension in a future use of\(\tau\)-Argus. A full description of the metadata file can be found in section[5.1]. When the data file has been selected and optionally the meta datafile, you can proceed to the menu options Specify|Metafile toedit/modify the meta data file and to Specify|Tables to specify thetables required. See section [4.4] and[4.4.4].
4.3.2 File | Open Table
This is the option allowing the input of tabular data into \(\tau\)-Argus. Inthis case, an already-constructed table is read in. This is reached byselecting ‘Open Table’ in the file menu of \(\tau\)-Argus. 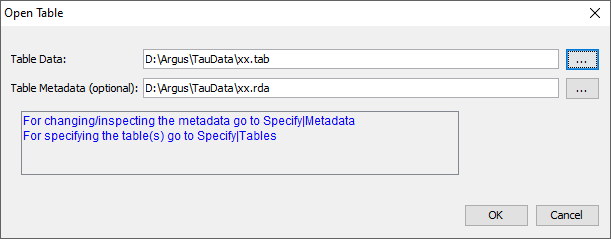 The name of the file containing the table to be opened (in the formatgiven below) needs to be specified in the first line. Optionally thename of the file containing the metadata is entered in the secondline. Later on you will be offered the option of adapting the metadataor even enter the metadata from scratch. There is a great flexibility with this option. The structure of the file is that each line/record describes one cellin free format. The separator is to be specified in the metadata. Themore detail is given for each cell, the more \(\tau\)-Argus can do for you. In any case for each cell the codes of the explanatory variables andthe cell value need to be given. Optionally the following informationcan be specified:
The name of the file containing the table to be opened (in the formatgiven below) needs to be specified in the first line. Optionally thename of the file containing the metadata is entered in the secondline. Later on you will be offered the option of adapting the metadataor even enter the metadata from scratch. There is a great flexibility with this option. The structure of the file is that each line/record describes one cellin free format. The separator is to be specified in the metadata. Themore detail is given for each cell, the more \(\tau\)-Argus can do for you. In any case for each cell the codes of the explanatory variables andthe cell value need to be given. Optionally the following informationcan be specified:
Frequency
Status
Cost variable
Shadow variable
Top-n variables
Lower and upper protection levels The more details are given for each cell to more flexibility \(\tau\)-Argusoffers in a later stage to apply sensitivity rules etc. If only the cell status is provided, \(\tau\)-Argus can only use that andgive each unsafe cell a fixed protection level of some percentage tobe specified. If also the largest say 2 contributors are provided,\(\tau\)-Argus can apply most of the sensitivity rules, like a p% rule of adominance rule (up to n=2). It is important
To stress that all the cells of a table have to be specified as > \(\tau\)-Argus will not compute any (sub-)totals. In most situations this > is simply impossible.
A table has to be additive. Theoretically this is trivial, but many > methods to protect a table even require strict additivity. After clicking ‘OK’ you can either proceed by adapting the metadatavia Specify|Metafile or by specifying the table details viaSpecify|Table. This (artificially generated) datafile shows 2 explanatory variables,cell value, cell frequency and the top 3 values in each cell. Withthis information τ‑argus is still able to apply the primarysensitivity rules, like p% rule. An example of a 2 dimensional table T, T, 2940 ,48, 200,200,200 T, A, 745 ,12, 200,100,100 T, B, 810 ,12, 200,100,100 T, C, 685 ,12, 200,100,100 T, D, 700 ,12, 200,100,100 1, T, 795 ,12, 200,100,100 1, A, 350 ,3, 200,100,50 1, B, 190 ,3, 100,50,40 1, C, 150 ,3, 100,40,10 1, D, 115 ,3, 50,40,25 2, T, 670 ,12, 200,100,100 2, A, 115 ,3, 50,40,25 2, B, 340 ,3, 200,100,40 2, C, 115 ,3, 50,40,25 2, D, 120 ,3, 100,10,10 3, T, 785 ,12, 200,100,100 3, A, 190 ,3, 100,50,40 3, B, 115 ,3, 50,40,25 3, C, 325 ,3, 200,100,25 3, D, 165 ,3, 100,40,25 4, T, 690 ,12, 200,100,100 4, A, 100 ,3, 50,25,25 4, B, 175 ,3, 100,50,25 4, C, 115 ,3, 50,40,25 4, D, 310 ,3, 200,100,10 Alternatively if only the status is given to τ‑argus , there is noother option than to use the status and treat all unsafe cells as’manually’ unsafe and apply the manual safety margin. T, T, 2940 ,u T, A, 745 ,s T, B, 810 ,s T, C, 685 ,s T, D, 700 ,s 1, T, 795 ,s 1, A, 350 ,s 1, B, 190 ,s 1, C, 150 ,s 1, D, 115 ,s 2, T, 670 ,s 2, A, 115 ,s 2, B, 340 ,s 2, C, 115 ,u 2, D, 120 ,u 3, T, 785 ,s 3, A, 190 ,s 3, B, 115 ,s 3, C, 325 ,s 3, D, 165 ,s 4, T, 690 ,s 4, A, 100 ,s 4, B, 175 ,s 4, C, 115 ,s 4, D, 310 ,s For tables of dimension 3 or higher, additional columns for theexplanatory variables need to be added as well as additional rows toallow for the increased depth of the table. The next step will be to optionally edit the metadata and then readthe table.
4.3.3 File | Open Table Set
When the linked tables procedure will be used in combination withtabular input, the option “Open Table Set” must be used to read a setof tables in τ‑argus. The “Open Table” option as described above([4.3.2]) allows for only one single individual table. In this option a set of tables with the corresponding metadata files(*.rda) is specified. Search for the tables in the familiar way and press “Add” to add thetable to the det of linked tables being build. When the set is complete, press the OK-button. 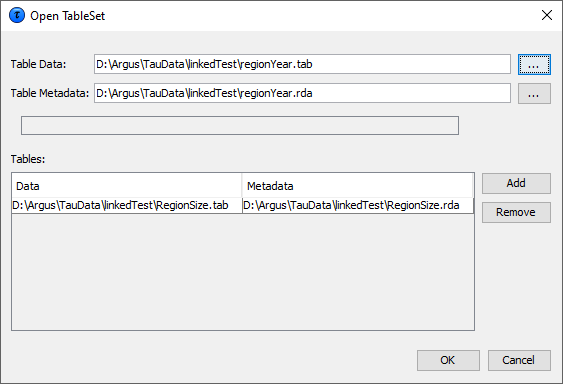 After pressing the OK-button, you will be guided automatically to theSpecify Tables window. This is described in section[4.4.5]. In the linked tables approach it is no longer possible to modify themetadata. As the same rules will be applied to each individual table, you willbe guided to the Specify Tables window only once. The choices will beapplied to each table. This implies that all tables in a linked set should have the sameadditional variables, as described in the previous section[4.3.2]. Please note that it is advisable to read each table individually inτ‑argus before. This to be sure that the specification of the tablesand the metadata is correct, before starting the linked tablesprocedure.
After pressing the OK-button, you will be guided automatically to theSpecify Tables window. This is described in section[4.4.5]. In the linked tables approach it is no longer possible to modify themetadata. As the same rules will be applied to each individual table, you willbe guided to the Specify Tables window only once. The choices will beapplied to each table. This implies that all tables in a linked set should have the sameadditional variables, as described in the previous section[4.3.2]. Please note that it is advisable to read each table individually inτ‑argus before. This to be sure that the specification of the tablesand the metadata is correct, before starting the linked tablesprocedure.
4.3.4 File | Open Batch Process
This option allows the user to run the commands in batch mode fromopening the microdata and metadata, protecting the table and creatingthe output of the final table(s). If the last line of the batch-file is <GOINTERACTIVE> \(\tau\)-Argus willfirst perform all the actions as specified in the batch-file and thenopen the main menu and giving the control to the user to continue thework in the interactive modus. The lay-out of the batch-file is described in section[5.7]. Note that a log file is maintained of all actions. This is the placeto look if something might go wrong, as a batch-process typically doesnot report to a GUI. By default the log file is “Logbook.txt” in thetemp-directory, but in the batch-file a different file can be chosen.Also from the command-line a log file name can be specified. See alsosection [5.7].
4.3.5 File | Exit
Exits the \(\tau\)-Argus-session.
4.4 The Specify menu
Themetadata structure is different for describing microdata and tabulardata. Therefor the structure of the metadata file (RDA-file) isdifferent and also the window to specify and modify the metadata isdifferent. The version presented depends on the type of data that hasbeen selected. We will first describe the situation for microdata(section [4.4.1]) and then for tabular data (section[4.4.3]).
4.4.1 Specify | Metafile [for microdata]
Clicking on ‘Specify|Metafile’ gives the user the opportunity toeither edit a metafile already read in or to enter the metadatainformation directly at the computer from scratch. In this dialog box all attributes of the variables can be specified.This is a good alternative to manually edit the rda-file outside\(\tau\)-Argus. \(\tau\)-Argus does a moderate checking of the rda-file, but noguarantee can be given for a proper functioning of a manually editedrda-file. The rda-file has been explained in detail in section[5.1]. Here, the editing of a rda-file within \(\tau\)-Argus islooked at. 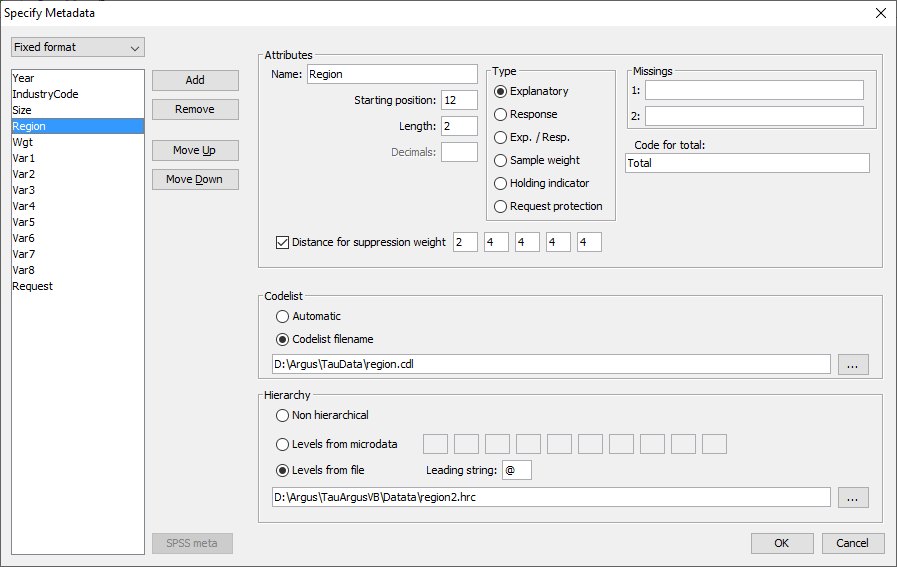 If under File|Open Microdata an rda-file has been specified, thisdialog box shows the contents of this file. If no .rda-file has beenspecified the information can be specified in this dialog box afterpushing the New button. As default "New" is substituted as thevariable name, but the user is expected to fill in a correct name.Apart from defining a new variable, an existing one can be modified ordeleted. In the left top field the file type (fixed, free format or SPSS) canbe specified. The following attributes for each variable can be specified or edited:
If under File|Open Microdata an rda-file has been specified, thisdialog box shows the contents of this file. If no .rda-file has beenspecified the information can be specified in this dialog box afterpushing the New button. As default "New" is substituted as thevariable name, but the user is expected to fill in a correct name.Apart from defining a new variable, an existing one can be modified ordeleted. In the left top field the file type (fixed, free format or SPSS) canbe specified. The following attributes for each variable can be specified or edited:
name of the variables
its first position in the data file (for fixed format)
its field-length
the number of decimals (for numerical variables).
Furthermore, the role of variable can be specified or edited (more > detail on these can be seen in section [4.3.1]):
explanatory variable: This can be used as a spanning variable in > the row or column of the table
response variable: This can be used as a cell-item
weight variable: This specifies the sampling-weight of the record > and is based on the sampling design used. The following are special variable types and have not been previouslydescribed. As they are specific to designating safety rules, moredetail is given in section [4.4.4]. Holding Indicator The Holding indicator: sometimes groups of records belong together.E.g. if a set of records describe the contributions of one business tovarious cells. So it could be better to apply the confidentialityprotection at the business level in all cells of the table, especiallythe marginal cells. This variable is the group identifier. \(\tau\)-Argusexpects the records of a group to be together in the input datafile.An example is shown in section [4.4.4]. Request Protection The Request protection option is used if the Request Rule under’Specify tables’ is to be applied. This variable indicates whether ornot a record asked for protection. This is further explained insection [4.4.4]. Additionally the codes specifying whethera respondent asked for asking protection is to be specified; twodifferent codes are possible, corresponding to two different sets ofparameters in the sensitivity rule. This rule is often used in ForeignTrade Statistics. Distance function When finding a pattern of secondary suppressions, most methods try tominimalize some kind of cost function. Often the costs are some valuelinked to each cell.users like to group the secondaries close to the primaries. Theadvantage is that loss of information is grouped in certain parts ofthe table. This can be achieved by used the distance function. The costs for eachcell depend on the number of steps the cell is apart from a primary.For each step the cost can be specified, with a maximum of 5. The distance function can only be applied in combination with themodular suppression method. Total code Optionally a code for the total can be chosen; the default is"Total". Additional Specifications Other attributes, which may be edited or specified are missing valueoptions, (optional, not required) codelist files, (optional, notrequired) hierarchies. Details on these options have been given in section[4.3.1]. In summary, for codelist the ‘automatic’ option simply generates thecodes from the data. Specifying a codelist, allows the user to supplyan additional file (usually .cdl) containing the labels attached tothe codes. These labels are used to enhance the information by \(\tau\)-Arguson the screen. In both cases \(\tau\)-Argus will use the codes that it findsin the datafile. Hierarchies can either be derived from the digits in the codes or froma file (usually .hrc) The RDA file Here is an example of a rda file for microdata. This has already beenshown in section [4.3.1] and is shown here forcompleteness. (Note, the dots at the bottom just means that here ashortened version of the file is presented.) Year 1 2 <RECODEABLE> IndustryCode 4 5 99999 <RECODEABLE> <HIERARCHICAL> <HIERLEVELS> 3 1 1 0 0 <DISTANCE> 1 3 5 7 9 Size 9 2 99 <RECODEABLE> <TOTCODE> Alles Region 12 2 <RECODEABLE> <CODELIST> "REGION.CDL" <HIERARCHICAL> <HIERCODELIST> "region2.hrc" <HIERLEADSTRING> "@" <DISTANCE> 2 4 4 4 4 Wgt 15 4 9999 <DECIMALS> 1 <WEIGHT> Var1 19 9 999999999 <NUMERIC> Var2 28 10 9999999999 <NUMERIC> <DECIMALS> 2 ……………… See also section [5.1.1] for a more detailed description τ‑argus can also read free format data files. In that case there areslight differences. You select free format in the combo box in theleft upper corner. And specify the separator used. The parameterstarting position is no longer valid and will not be visible.
4.4.2 Specify | Metafile [SPSS System files]
When \(\tau\)-Argus works with a SPSS system file the specification of themeta data is twofold. The data is stored in the SPSS system file andalso the metadata. But the metadata available in the SPSS system fileis not enough for τ‑argus. E.g. no information on hierarchies isavailable. So the SPSS metadata is only a starting point. The metadatahas to be extended. The procedure is that τ‑argus will retrieve theSPSS meta data and then expects the user to extend the metadata, usingthe familiar window; see section [4.4.1]. However certainvariables in the metadata cannot be changed any more as we have toguarantee that the extended metadata is still applicable to the SPSSsystem file. E.g. the length of the variables cannot be modified northe number of decimals nor the name. Selecting the variables. If no RDA file but only the SPS-system file has been specified youhave to select the variables of interest running \(\tau\)-Argus. At thebottom of the metadata window you will find a button “SPSS meta”. Thiswill bring you to a window showing all variables available. Make aselection. 
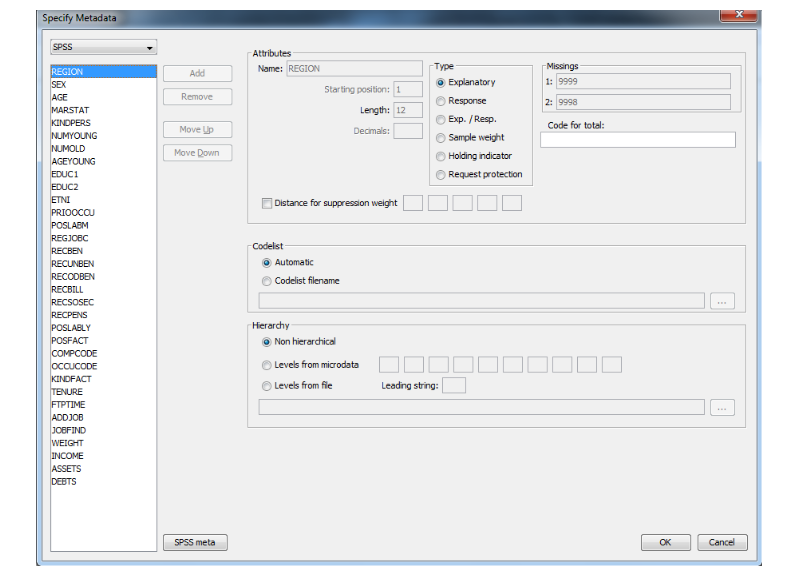
4.4.3 Specify | Metafile [for tabular data]
When a tabular datafile has been selected, the metadata window willhave a different form. Clicking on ‘Specify|Metafile’ gives theopportunity to either edit the metafile already read in or to enterthe metafile information directly at the computer. In section[5.1.4] a detailed description of the metafile fortabular data can be found Below is displayed the ‘Specify metafile’ window for tabular inputdata. Above the list of variables the separator used to separate thevariables in the datafile can be specified. Here, the variables can be specified or edited as required. The options are:
‘Explanatory’ – The spanning variables used to produce the table.
‘Response’– The variable used to calculate the cell total.
‘Shadow’– The variable is used as a shadow variable.
‘Cost’– The variable is used as the cost-variable.
‘Lower prot .Level’ – The lower protection level
‘Upper prot. Level’ – The upper protection level
‘Frequency’ – This indicates the number of observations making up > the cell total. If there is no frequency variable each cell is > assumed to consist of a single observation.
‘topN variable’ – This shows if this variable is defined as one of > the top N contributors to the cell. The pre-defined value for TopN > is 1. The first variable declared as ‘topN’ will contain the > largest values in each cell, the second variable so declared will > contain the second largest values etc.
‘Status indicator’ – allows a variable in the left-hand pane to be > declared as a Status Indicator. Typically cells can be declared as > Safe, Unsafe or Protected.
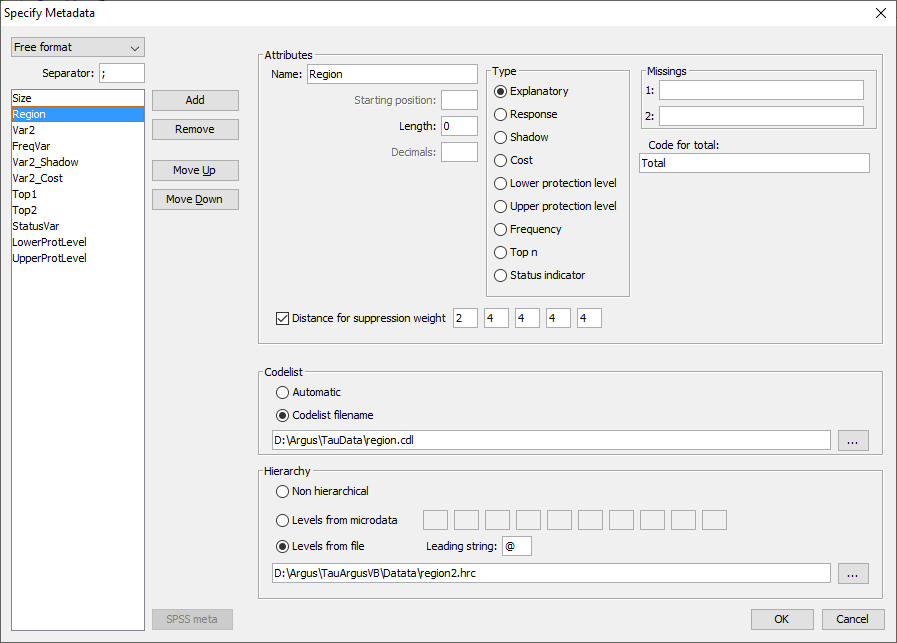 The codelist and the hierarchy are the same as for microdata, so werefer to section [4.4.1]. For explanatory variables the code for the total has to be specified.We strongly recommend strongly that the user also provides the valuesfor the totals himself, but if needed he can ask \(\tau\)-Argus to computethese totals. However it should be noted that when the option tocompute the totals by \(\tau\)-Argus is selected you will lose vitalinformation as the cell status. See also section [4.4.5]In any case, \(\tau\)-Argus needs these totals as they play an important roleis the structure of a table and also are important for the suppressionmodels.
The codelist and the hierarchy are the same as for microdata, so werefer to section [4.4.1]. For explanatory variables the code for the total has to be specified.We strongly recommend strongly that the user also provides the valuesfor the totals himself, but if needed he can ask \(\tau\)-Argus to computethese totals. However it should be noted that when the option tocompute the totals by \(\tau\)-Argus is selected you will lose vitalinformation as the cell status. See also section [4.4.5]In any case, \(\tau\)-Argus needs these totals as they play an important roleis the structure of a table and also are important for the suppressionmodels.
4.4.4 Specify | Specify Tables [for microdata]
In this dialog box the user can specify the tables which requireprotection. In one run of \(\tau\)-Argus more than one table can bespecified, but the tables will be protected separately unless they arelinked (have at least one variable in common). In that case they canbe protected simultaneously if required. In section[4.5.2] the idea of linked tables will be discussed. Also, the user has to specify the parameters for the dominance rule orp% rule and the minimum number of contributors in a cell, etc. Atpresent \(\tau\)-Argus allows up to 6-dimensional tables, but due to thecapacities of the LP-solver used (either Xpress or cplex depending onthe user’s license or the free solver) and the complexity of theoptimisations involved, tables of this complexity can only beprotected by the hypercube method (see section [2.8] inthe Theory chapter). The solutions based on optimisation are limitedto 4 dimensions. Below is a typical window obtained when specifying tables with thep%-rule applied. 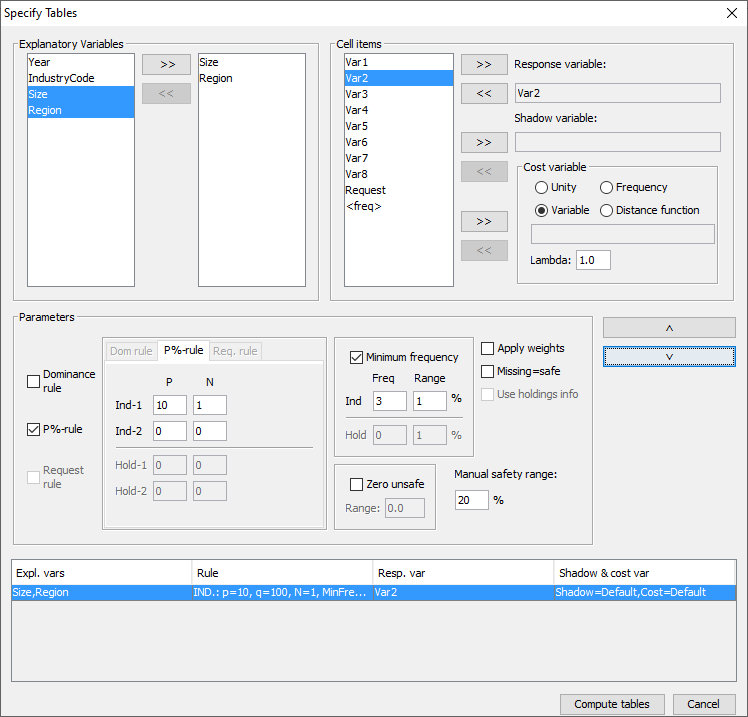 In section [4.4] details of variable definitions in themetafile were explained. Now consider how the variables defined in themetafile are used to create a table along with an associated safetyrule. The explanatory (or spanning) variables On the left is the listbox with the explanatory variables. When the user clicks on ‘>’ or ‘<’ the selected variable istransported to the next box. From the left box with explanatoryvariables the user can select the variables that will be used as thespanning variables in the row or the column of the table. Cell items Here, is a list of variables that can be used as response, shadow orcost variables in the disclosure control. By pressing the '>' or'<' they can be transferred to or from the windows on the right. The response variable From the list of cell items the user can select a variable as aresponse variable. This is the variable for which the table to beprotected is calculated. If <freq> is selected a frequency table will be computed. As theneither dominance rule nor the p% rule are meaningful in thissituation, they cannot be used for frequency tables. The shadow variable The shadow variable is the variable that is used to apply the safetyrule. By default this is the response variable, but it is possible toselect another variable. The safety rules are built on the principleof the characteristics of the largest contributors to a cell. If avariable other than the response variable is a better indicator thisvariable can be used here; e.g. the turnover (a proxy for the size ofthe enterprise) can be a suitable variable to apply the safety rule,although the table is constructed using another (response) variable. The cost variable This variable describes the costs of suppressing each individual cell;these costs are used by the internal workings of the secondarysuppression routines. Note that the choice of the cost variable doesnot have any effect when the hypercube method is used for secondarycell suppression. See 2.7.1 for information about how cell costs aredetermined during execution of the hypercube method. With exception ofthe hypercube method, these costs are minimised when the secondarysuppressed cells are determined. By default, this is the responsevariable but two other choices are possible as well as the use of adifferent response variable. Use the frequency of the cells as a cost-function: this will minimisethe number of records contributing to the cells to be suppressed. The number of cells to be suppressed is minimised, irrespective of thesize of their contributions (Unity option). However this might lead tothe suppression of many marginal. A Box-Cox like-transformation can be applied to the individual valuesof the cost variable before minimisation of the cost function. Thesimplified Box Cox function used here is xλ where x is the costvariable and λ is the transformation parameter. For example if λ = 0.5a square root transformation is used and if λ =0 a log transformationwill be applied. Applying this to the unity-choice is rathermeaningless. Weight If the data file has a sample weight, specified in the metadata, thetable can be computed taking these weights into account. If the ‘Apply Weights’ box is ticked, the weights are applied to thecell entries as for the simple application of normal sampling weightsin a survey. In addition these weights are used in applying the safetyrules. When we have a sample the normal idea behind the sensitivityrules that the largest contributions can make a good estimate of eachother is no longer valid. The solution is that we artificially createa complete cell by assuming that each contribution is in fact as manycontributions as its sample weight. And we apply the sensitivity ruleson this cell. An example might help here. For example if there is a cell with two contributions: 100, weight 4 10, weight 7 The cell value = (4 x 100) + (7 x 10) = 470. Without considering theweights there are only two contributors to the cell 100 and 10.However by taking account of the sampling weights the cell values areapproximately 100, 100, 100, 100, 10, 10, 10, 10, 10, 10 and 10. Thelargest two contributors are now 100 and 100. These are regarded asthe largest two values for application of the safety rules. If theweights are not integers, a simple extension is applied. The safety rule The concept of safety rules is explained in section [2.2]On the left side of the window the type of rule that can be selectedalong with the value of the parameters is shown. The possible rulesare:
In section [4.4] details of variable definitions in themetafile were explained. Now consider how the variables defined in themetafile are used to create a table along with an associated safetyrule. The explanatory (or spanning) variables On the left is the listbox with the explanatory variables. When the user clicks on ‘>’ or ‘<’ the selected variable istransported to the next box. From the left box with explanatoryvariables the user can select the variables that will be used as thespanning variables in the row or the column of the table. Cell items Here, is a list of variables that can be used as response, shadow orcost variables in the disclosure control. By pressing the '>' or'<' they can be transferred to or from the windows on the right. The response variable From the list of cell items the user can select a variable as aresponse variable. This is the variable for which the table to beprotected is calculated. If <freq> is selected a frequency table will be computed. As theneither dominance rule nor the p% rule are meaningful in thissituation, they cannot be used for frequency tables. The shadow variable The shadow variable is the variable that is used to apply the safetyrule. By default this is the response variable, but it is possible toselect another variable. The safety rules are built on the principleof the characteristics of the largest contributors to a cell. If avariable other than the response variable is a better indicator thisvariable can be used here; e.g. the turnover (a proxy for the size ofthe enterprise) can be a suitable variable to apply the safety rule,although the table is constructed using another (response) variable. The cost variable This variable describes the costs of suppressing each individual cell;these costs are used by the internal workings of the secondarysuppression routines. Note that the choice of the cost variable doesnot have any effect when the hypercube method is used for secondarycell suppression. See 2.7.1 for information about how cell costs aredetermined during execution of the hypercube method. With exception ofthe hypercube method, these costs are minimised when the secondarysuppressed cells are determined. By default, this is the responsevariable but two other choices are possible as well as the use of adifferent response variable. Use the frequency of the cells as a cost-function: this will minimisethe number of records contributing to the cells to be suppressed. The number of cells to be suppressed is minimised, irrespective of thesize of their contributions (Unity option). However this might lead tothe suppression of many marginal. A Box-Cox like-transformation can be applied to the individual valuesof the cost variable before minimisation of the cost function. Thesimplified Box Cox function used here is xλ where x is the costvariable and λ is the transformation parameter. For example if λ = 0.5a square root transformation is used and if λ =0 a log transformationwill be applied. Applying this to the unity-choice is rathermeaningless. Weight If the data file has a sample weight, specified in the metadata, thetable can be computed taking these weights into account. If the ‘Apply Weights’ box is ticked, the weights are applied to thecell entries as for the simple application of normal sampling weightsin a survey. In addition these weights are used in applying the safetyrules. When we have a sample the normal idea behind the sensitivityrules that the largest contributions can make a good estimate of eachother is no longer valid. The solution is that we artificially createa complete cell by assuming that each contribution is in fact as manycontributions as its sample weight. And we apply the sensitivity ruleson this cell. An example might help here. For example if there is a cell with two contributions: 100, weight 4 10, weight 7 The cell value = (4 x 100) + (7 x 10) = 470. Without considering theweights there are only two contributors to the cell 100 and 10.However by taking account of the sampling weights the cell values areapproximately 100, 100, 100, 100, 10, 10, 10, 10, 10, 10 and 10. Thelargest two contributors are now 100 and 100. These are regarded asthe largest two values for application of the safety rules. If theweights are not integers, a simple extension is applied. The safety rule The concept of safety rules is explained in section [2.2]On the left side of the window the type of rule that can be selectedalong with the value of the parameters is shown. The possible rulesare:
Dominance Rule
P% Rule
Request Rule (this rule is described in detail later in this > section) Additionally, the minimum number of contributors may be chosen (in the'minimum frequency' box). Two dominance rules and two P% rules can be applied to each table.When 2 rules are specified, for a cell to be declared non-disclosive,it must satisfy both rules. Dominance Rule This is sometimes referred to as the (n,k) rule where n is the numberof contributors to a cell contributing more than k% of the total valueof the cell (if the cell is to be defined as unsafe). A popular choicewould be to set n equal to 3 and k equal to 75%. An example of thewindow when specifying a single dominance rule is shown at the startof this section. P% rule The p% rule says that if x1 can be determined to an accuracy ofbetter than P% of the true value then it is disclosive where x1is the largest contributor to a cell. The rule can be written as: \[{{\sum\limits_{i = 3}^{c}x_{i}} \geq \frac{p}{100}}x_{1}\] for thecell to be non-disclosive where c is the total number ofcontributors to the cell and the intruder is a respondent in the cell. It is important to know that when entering this rule in \(\tau\)-Argus thevalue of N refers to the number of intruders in coalition (who wishto group together to estimate the largest contributor). A typical example would be that the sum of all reporting unitsexcluding the largest two must be at least 10% of the value of thelargest. Therefore, in \(\tau\)-Argus set p=10 and n =1 as there is just oneintruder in the coalition, respondent x2. For the dominance rule and the p%-rule the safety ranges required(as a result of applying the rule) can be derived automatically. Thetheory gives formulas for the upper limit only, but for the lowerlimit there is a symmetric range. See e.g. Loeve (2001). (This isreferenced in Section [2.2] (Theory)) As this rule focusses better on the protection of individualcontributors the \(\tau\)-Argus team is convinced that the p%-rule is to bepreferred over the dominance rule. This is also the advice in Europe. Request Rule This is a special option applicable in certain countries relating toe.g. foreign trade statistics. Here, cells are protected only when thelargest contributor represents over (for example) 70% of the total andthat contributor asked for protection. Therefore, a variableindicating the request is required. This option requires an additional variable in the data, with e.g. 0representing no request for that particular business, and 1representing a request where the particular cell value is > x% of thecell total. In fact there is an option for two different thresholds.The min freq is interpreted such that if a cell has at least onerequest and the cell-freq is below the freq-threshold, that cell isconsidered to be unsafe as well. Even if the request is not thelargest one. The idea is that in that case a large non requestingcontributor could reveal the smaller requesting contributor. Note that the 3 rules (dom. rule, p% rule and request rule) do notmake any sense if there are positive and negative contributions to acell. Minimum Frequency If this box is checked, a rule controlling the minimum number of****contributors to a cell will be specified. If the number ofcontributors is less than this value, the cell is considered unsafe. Freq Here, the minimum number of** contributors can be stated. This issometimes known as the threshold rule. It is also possible to specifyno safety rule apart from a minimum frequency value. Frequency-range As described above, for the dominance rule and the P%-rule safetyranges can be derived automatically. However, the theory does notprovide any safety range for the minimum frequency rule. Therefore,the user must provide a safety-range percentage required to allowsecondary suppressions to be carried out. For example, if this valuewas set to equal 30%, it would mean an attacker would not be able tocalculate an interval for this cell to within 30% of the actual valuewhen looking at the safe output. Following this, the secondarysuppressions may be carried out. Manual Safety Range When a cell is set manually unsafe (an option to discussed later),\(\tau\)-Argus cannot calculate safety-ranges itself. Therefore, the usermust supply a safety-percentage for this option for the same reasonsas in the above section, to allow secondary suppressions to beapplied. Zero Unsafe If all contributions to a cell are zero, the cell value will be zerotoo. Applying sensitivity rules here has some problems. Is the sum ofthe largest 3 zeros larger than zero? Nevertheless all contributionsto this cell can be easily disclosed. If cells with totalcontributions of zero are to be regarded as unsafe, this box has to bechecked. A manual safety range will also be required, not as apercentage but as a value at the level of the cell-item. Missing = safe If one of the spanning variables of a cell has a code missing, thiscell is often no longer sensitive. The idea behind this is that therespondent in this cell is not identifiable. When this option ischecked, all cells for which at least one spanning variable has amissing value is considered safe, whatever all the sensitivity rulessay. If this option is not checked the normal procedures as for allother cells are applied. Holding Indicator** **** This section on the Holding Indicator is best read after section[4.2] In some countries, confidentiality protection is applied to businessesat different levels. For example, as in the U.K. a number of’reporting units’ (the lower level of unit) within a cell might belongto an ‘enterprise group’ (higher level). The level at which theconfidentiality rule is applied clearly matters. The holding indicatorallows such groupings to be defined and used in one or more of thesafety rules. This is now illustrated with an example looking at both the p% ruleand the threshold rule at the same time.
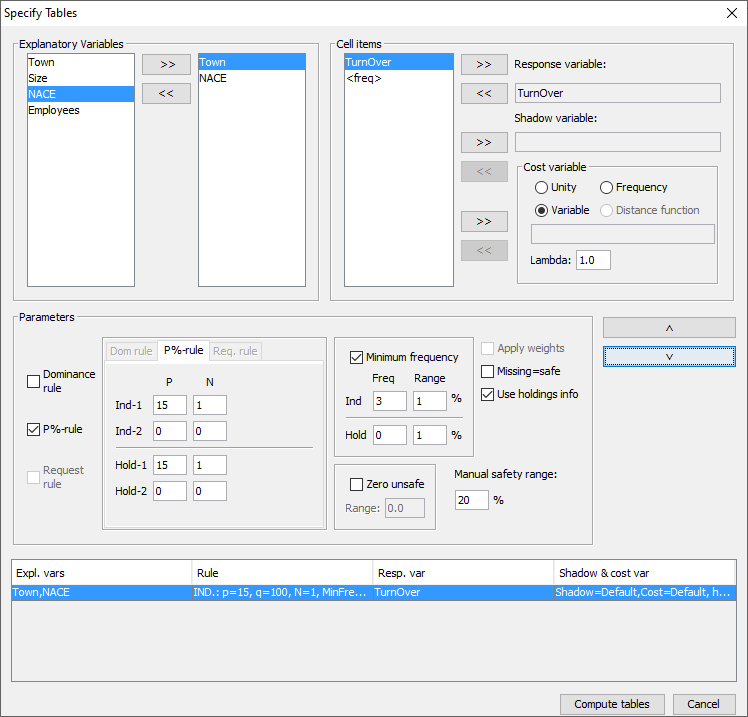 Consider the following dataset
Consider the following dataset
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Assume the following safety rules
Threshold rule: At least 3 enterprise groups (higher level units) in > a cell
P% rule: The sum of all the reporting units (lower level units) > excluding the largest 2 must be at least 10% of the value of the > largest. There are 4 cells in the table along with the margins. The cell we areinterested in here is Cellref 900,30: 5 reporting units, 4enterprise groups At the reporting unit the values are 700,200,60,40,10 At the enterprise group the values are 900,60,40,10 This rule has been designed so that when the P% rule is applied tothis cell: With reporting units the cell is safe. 10+60+40 = 110. This is greaterthan 10% of the largest value (70) so the cell is safe. With enterprise groups the cell is unsafe. 40+10 = 50. This is lessthan 10% of the largest value (90) so the cell is unsafe. Apply the threshold rule to the enterprise groups (Hold. =3) and P%rule to the reporting units. Once again a safety range percentage is required. The output from the application of this rule is shown below. Two cellsfail the threshold rule with the holding rule applied. The threshold rule has been applied correctly using the holdingindicator as the correct cells are safe (that would be unsafe if theholding indicator was not being used). After all the options have been selected compute the table When all the necessary information has been given, click '˅' totransport all the specified parameters to the ‘listwindow’ on thebottom. As many tables as required can be specified but as the size ofthe memory of a computer is restricted it is not advisable to selecttoo many tables. To modify an already made table press the ‘^’button. Click on ’Compute Tables’ to compute the tables. In case of a SPSSsystem file SPSS will first be called to export the necessarymicrodata automatically to a scratch fixed format ASCII file in theTEMP directory. When the table(s) has been computed, the first table will be shown.
4.4.5 Specify | Specify tables [for tabular data]
When the ‘Specify|Metafile’ option is followed the ‘Specify|Tablemetadata’ option is also available and the window is displayed here.This will allow the application of safety rules such as the DominanceRule and the P% rule. Section [4.4.4] (specifying tablesfrom microdata) will explain these safety rules and other options indetail. 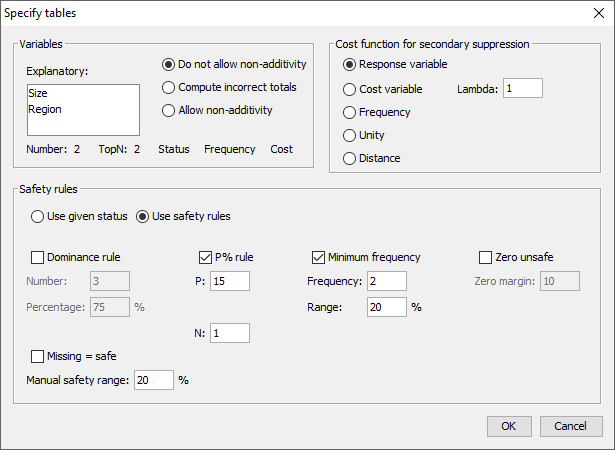 In the safety rule frame, the type of rule can be selected along withthe value of the parameters. These are the dominance rule and P% rule.Additionally, the minimum number of contributors can be chosen(threshold rule), via ticking and filling-in the minimum frequencybox. If both the status and some information to apply the sensitivityrules have been supplied, both options ‘use given status’ and ‘usesafety rules’ are enabled and the user can chose which one to use. Depending one the amount of detail in the table file some options willbe disabled. If no top1 and top2 information is provided, the p%-rulecannot be used. There is an option to calculate the possibly missing marginals andtotals. This option should be used only as an emergency. It is alwaysbetter to provide τ‑argus with a full, complete table. When \(\tau\)-Argushas to compute these marginals all safety information will be ignored. When all the options have been completed, pressing the ‘OK’ buttonwill invoke \(\tau\)-Argus to actually compute the table requested. Now theprocess of disclosure control can begin.
In the safety rule frame, the type of rule can be selected along withthe value of the parameters. These are the dominance rule and P% rule.Additionally, the minimum number of contributors can be chosen(threshold rule), via ticking and filling-in the minimum frequencybox. If both the status and some information to apply the sensitivityrules have been supplied, both options ‘use given status’ and ‘usesafety rules’ are enabled and the user can chose which one to use. Depending one the amount of detail in the table file some options willbe disabled. If no top1 and top2 information is provided, the p%-rulecannot be used. There is an option to calculate the possibly missing marginals andtotals. This option should be used only as an emergency. It is alwaysbetter to provide τ‑argus with a full, complete table. When \(\tau\)-Argushas to compute these marginals all safety information will be ignored. When all the options have been completed, pressing the ‘OK’ buttonwill invoke \(\tau\)-Argus to actually compute the table requested. Now theprocess of disclosure control can begin.
4.5 The Modify menu
4.5.1 Modify | Select Table
This dialog box enables the user to select the table they want to see.If the user has specified only one table, this table will be selectedautomatically and this option cannot be accessed. In the examplewindow shown here the first table is a 2 dimensional table (Size xRegion) followed by a 3 dimensional table (Size x Region xIndustryCode). Select the table to be processed and press theOK-button. 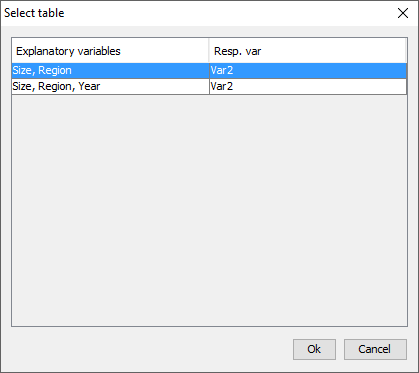
4.5.2 Modify | Linked Tables
This option is available when the tables specified have at least oneexplanatory or spanning variable in common and have the same responsevariable. When the tables are built from micro data, the tables can be specifiedusing the screen below. See also section [4.4.4]. An example is shown. 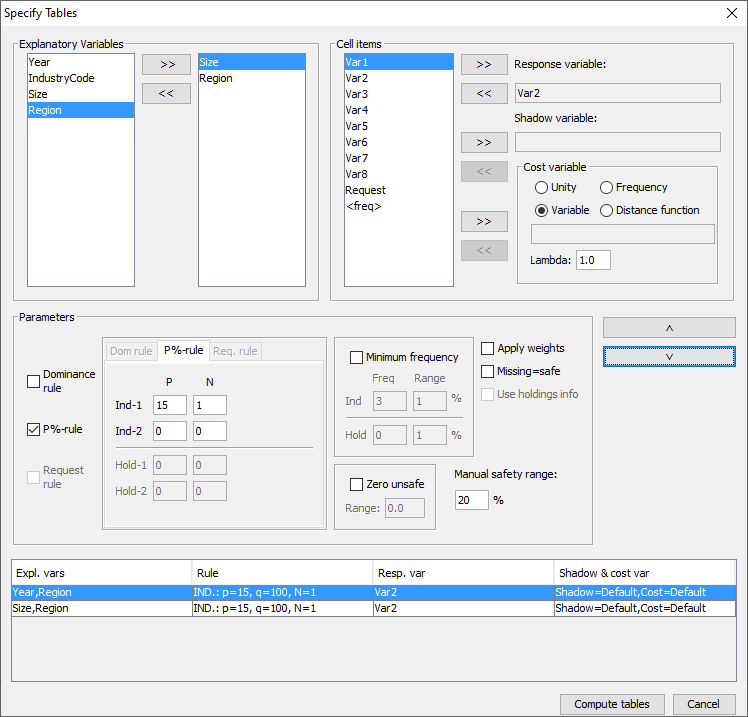 When the tables are supplied to τ‑argus as tabular input see section[4.3.3] (Open Table set). When supplying a set of readymade tables it should be clear to τ‑argus which explanatory variablesare in fact the same dimension. They should have the same name, evenif the level of detail is different. The next step is to further define the tables. This is similar to theprocedure in Specify Tables (see section [4.4.5]). Thesame choices for the parameters etc. are applied to each table. Itwill be clear that all tables should have the same amount of detail.Otherwise the choices cannot be applied to all tables. So it is notpossible that one table just has a Status indicator and another tablehas the top-2 allowing for applying the p%-rule.
When the tables are supplied to τ‑argus as tabular input see section[4.3.3] (Open Table set). When supplying a set of readymade tables it should be clear to τ‑argus which explanatory variablesare in fact the same dimension. They should have the same name, evenif the level of detail is different. The next step is to further define the tables. This is similar to theprocedure in Specify Tables (see section [4.4.5]). Thesame choices for the parameters etc. are applied to each table. Itwill be clear that all tables should have the same amount of detail.Otherwise the choices cannot be applied to all tables. So it is notpossible that one table just has a Status indicator and another tablehas the top-2 allowing for applying the p%-rule.  E.g. if a regional variable is an explanatory variable in two tables,but in one table it is at the level of province and in the other atthe level of municipality, they should nevertheless have the samename. If not τ‑argus will not recognise them as a link. The set of linked tables can be protected using the hypercube (seesection [2.8]) and the extended modular approach(see section [2.11]). When protecting a set of linked tables the restriction is that alltables are a sub-set of a theoretical cover table. The cover table isformed by building a table spanned by all explanatory variable fromthe individual tables and using the longest code list for eachdimension. The dimensions are decided by looking for different namesof explanatory variables. As long as the cover table does not have more than 10 dimensions andall the individual tables have not more that 4 dimensions, the linkedtables approach is possible. In the current implementation there is one restriction. For each ofthe spanning variables in the cover table the codelist and thehierarchy should be present in one of the linked tables. For all othertables the codelists and the hierarchy should be a subset of thiscover hierarchy. And of course the set of linked tables should beconsistent. The cells that are logical the same should have exactlythe same value and status. If not the protection of the cover tablewill fail. When tabular data is the starting point, it is the responsibility ofthe user that the tables are consistent. This means that the cellvalues of corresponding cells** **are the same and also the status. Ifnot this is an inconsistent situation. The modular approach is verystrict on complete additivity, as the optimisation routines behindmodular require this. The hypercube is a bit more relaxed.
E.g. if a regional variable is an explanatory variable in two tables,but in one table it is at the level of province and in the other atthe level of municipality, they should nevertheless have the samename. If not τ‑argus will not recognise them as a link. The set of linked tables can be protected using the hypercube (seesection [2.8]) and the extended modular approach(see section [2.11]). When protecting a set of linked tables the restriction is that alltables are a sub-set of a theoretical cover table. The cover table isformed by building a table spanned by all explanatory variable fromthe individual tables and using the longest code list for eachdimension. The dimensions are decided by looking for different namesof explanatory variables. As long as the cover table does not have more than 10 dimensions andall the individual tables have not more that 4 dimensions, the linkedtables approach is possible. In the current implementation there is one restriction. For each ofthe spanning variables in the cover table the codelist and thehierarchy should be present in one of the linked tables. For all othertables the codelists and the hierarchy should be a subset of thiscover hierarchy. And of course the set of linked tables should beconsistent. The cells that are logical the same should have exactlythe same value and status. If not the protection of the cover tablewill fail. When tabular data is the starting point, it is the responsibility ofthe user that the tables are consistent. This means that the cellvalues of corresponding cells** **are the same and also the status. Ifnot this is an inconsistent situation. The modular approach is verystrict on complete additivity, as the optimisation routines behindmodular require this. The hypercube is a bit more relaxed. 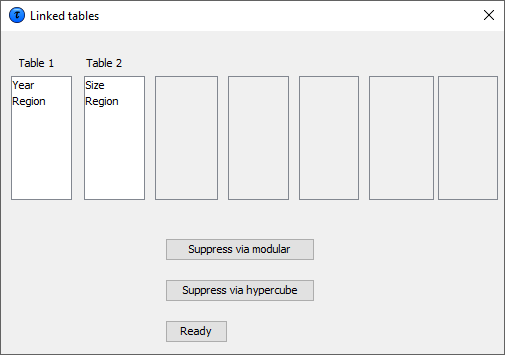 The set of linked tables can now be protected by pressing ‘Suppressvia modular’ or ‘suppress via hypercube’. \(\tau\)-Argus will then start anautomatic procedure. When the modular approach is selected, the subtables will be loaded inthe cover table. The cover table will then be protected via an extrabatch-run of τ‑argus and in the end the results (suppression pattern)will be transferred to the original subtables. If this procedure mightfail, information could be found in the log-file of τ‑argus. See alsosection [5.8]. Modular will ask for the selection of the singleton rules as usual.
The set of linked tables can now be protected by pressing ‘Suppressvia modular’ or ‘suppress via hypercube’. \(\tau\)-Argus will then start anautomatic procedure. When the modular approach is selected, the subtables will be loaded inthe cover table. The cover table will then be protected via an extrabatch-run of τ‑argus and in the end the results (suppression pattern)will be transferred to the original subtables. If this procedure mightfail, information could be found in the log-file of τ‑argus. See alsosection [5.8]. Modular will ask for the selection of the singleton rules as usual. 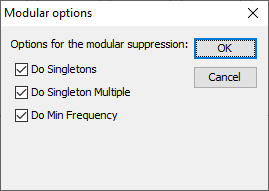 When making the cover table \(\tau\)-Argus will check for consistencies. E.gcells that are in the overlapping part of a table and who are bydefinition equal should have the same value status, protection leveletc. If \(\tau\)-Argus finds some inconsistencies, it will be reported.
When making the cover table \(\tau\)-Argus will check for consistencies. E.gcells that are in the overlapping part of a table and who are bydefinition equal should have the same value status, protection leveletc. If \(\tau\)-Argus finds some inconsistencies, it will be reported. 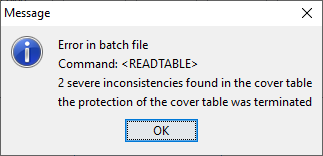 In the example the value of cell “Total,Nr”(4373664.0) and “12,Total” (1441228.0) are not correct. In twodifferent input files the status is not equal.
In the example the value of cell “Total,Nr”(4373664.0) and “12,Total” (1441228.0) are not correct. In twodifferent input files the status is not equal. 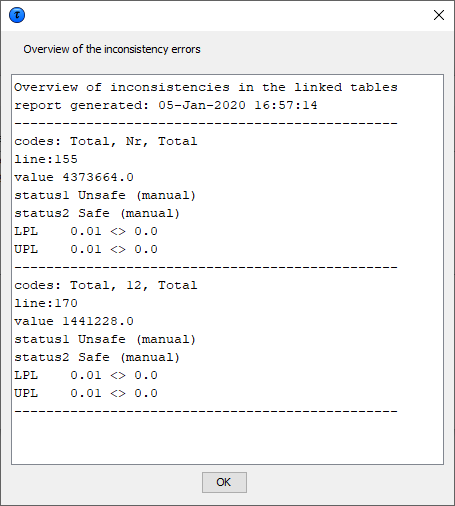 When the hypercube is selected, all the input files for the hypercubewill be prepared and the linked table procedure of the hypercube willbe started to protect the set of tables. Also the hypercube does notlike inconsistencies in e.g. the status. These will be reported in thefile PROTO002 in the temp-directory.
When the hypercube is selected, all the input files for the hypercubewill be prepared and the linked table procedure of the hypercube willbe started to protect the set of tables. Also the hypercube does notlike inconsistencies in e.g. the status. These will be reported in thefile PROTO002 in the temp-directory. 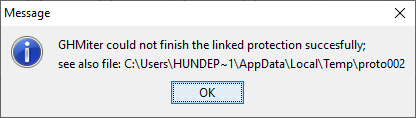 If successful the following information will be shown:
If successful the following information will be shown: 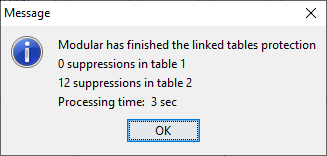 When the protection has been completed, the linked tables procedurecan be closed and the individual protected subtables can be inspectedand stored as normal tables.
When the protection has been completed, the linked tables procedurecan be closed and the individual protected subtables can be inspectedand stored as normal tables.
4.6 The Output menu
4.6.1 Output | Save Table
There are six options of saving the tables 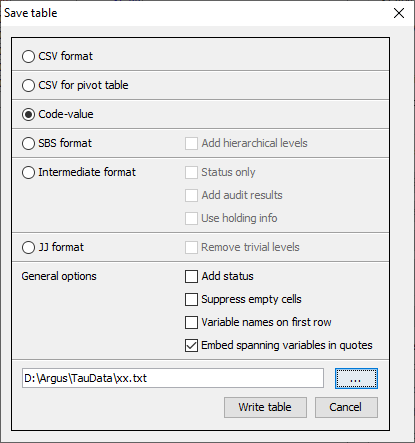 As a CSV file. This Comma Separated file can easily be read intoExcel. Please note the Excel should interpret the comma as aseparator. If your local settings are different you could use theExcel option ‘Data|Text to Columns’, This a typical tabular outputmaintaining the appearance of the table in \(\tau\)-Argus. CSV-file for a pivot table. This offers the opportunity to makeuse of the facilities of pivot table in Excel. The status of each cellcan be added here as an option (Safe, Unsafe or Protected forexample). The information for each cell is displayed on a single lineunlike standard csv format A text file in the format code-value, this is separated by commas.Here, the cell status is again an option. Also empty cells can besuppressed from the output file if required. The information for eachcell is displayed on a single line similar to the CSV file for a pivottable. There are two possibilities. Either the unsafe cells are shownas an ‘x’, as it should be in the final publication or the exactstatus can be printed in the output file in addition to the cellvalue. Optionally empty cells can be suppressed. When the status is added to the output file \(\tau\)-Argus can use 14different statuses. They can also be found in the report file.
As a CSV file. This Comma Separated file can easily be read intoExcel. Please note the Excel should interpret the comma as aseparator. If your local settings are different you could use theExcel option ‘Data|Text to Columns’, This a typical tabular outputmaintaining the appearance of the table in \(\tau\)-Argus. CSV-file for a pivot table. This offers the opportunity to makeuse of the facilities of pivot table in Excel. The status of each cellcan be added here as an option (Safe, Unsafe or Protected forexample). The information for each cell is displayed on a single lineunlike standard csv format A text file in the format code-value, this is separated by commas.Here, the cell status is again an option. Also empty cells can besuppressed from the output file if required. The information for eachcell is displayed on a single line similar to the CSV file for a pivottable. There are two possibilities. Either the unsafe cells are shownas an ‘x’, as it should be in the final publication or the exactstatus can be printed in the output file in addition to the cellvalue. Optionally empty cells can be suppressed. When the status is added to the output file \(\tau\)-Argus can use 14different statuses. They can also be found in the report file.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Note: 7 and 8 are no longer used. But in order to be compatible witholder versions of \(\tau\)-Argus we did not change the numbers. A SBS-format file. This file contains the information required byEurostat for different surveys like the SBS-survey. Each linedescribes one cell in the table. First all the spanning variables,with the levels in the hierarchy, then the cell value, the cellfrequency, the status and the dominance percentage. If the 2 largestcontributors have been computed this percentage is the sum of thelargest two, otherwise the largest one. It will be obvious that thisoutput format is not possible if a table has been used as input, withonly the status or maybe a cell frequency. The cell status can be:
|
|
|
|
|
|
|
|
|
|
A file in intermediate format for possible input into anotherprogram. This contains protection levels and external bounds for eachcell. This file could even be read back into \(\tau\)-Argus, using the readtables option The options are:
Write only the status
Add the results of the audit procedure (realised lower and upper > bounds)
Write information at the holding level, like the frequency.
Suppress the empty cells. Of course certain options are only available if appropriate. Finally, a report will be generated to a user specified directory.This report will be shown, when the table has been written. As this isan HTML-file; it can be viewed easily later. A file in JJ-format. This is an intermediate format used inτ‑argus. See section [5.5]. Some options are applicable to several output-versions. These aregrouped together under “General Options”.
4.6.2 Output | View Report
Views the report file which has been generated with Output|SaveTable. An example of a part of the output HTML file is shown here. As can be seen the essential information, for somebody other than theuser, about which rules have been applied to make the data safe isdisplayed along with details of any recoding. If required the reportcan be printed as well. 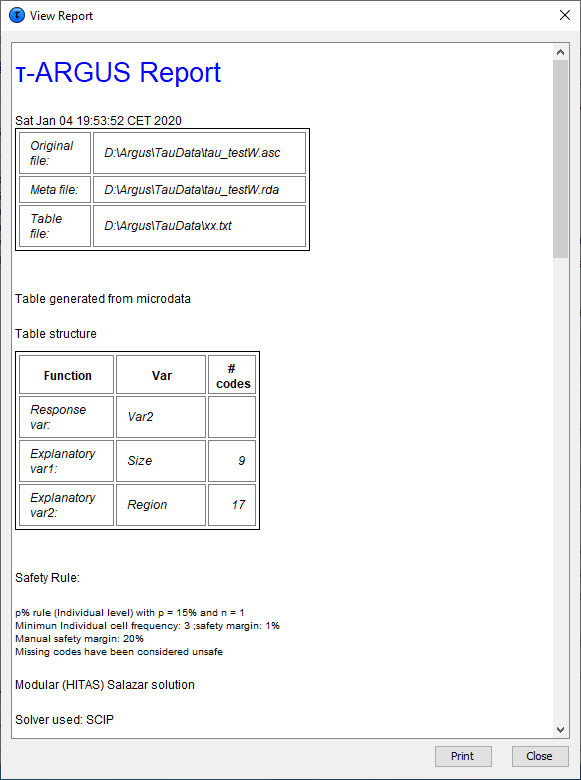 A nicer view of the report will be obtained if you open the report ina web-browser:
A nicer view of the report will be obtained if you open the report ina web-browser: 
4.6.3 Output | Generate apriori
In many situations it is desirable to coordinate the secondarysuppressions between tables. This can be because of links betweentables. Suppressions in one table should also be suppressions on theother table. But also when protecting monthly tables it could be a good idea tocoordinate suppressions between the different months. A secondarysuppression in month 1 could be an ideal candidate for secondarysuppression in month 2. This could be achieved by changing thesuppression weights for these cells. The apriori option is the way to change the default suppressionweights etc. But this leaves the task of generating the apriori file. Via this option the protected file as generated by \(\tau\)-Argus can beconverted into an apriori file. The table has to be saved in theformat code-value with the ‘Add Status’-option selected. For each status the user can select which action in the apriori filehas to be created. This can be a change of the suppression weight,give a new status, or nothing at all. The user has to specify the protected file (written in the rightformat (saved as code/value plus status) and the apriori file to begenerated. Also the correspondence between the variables must be specified. It isnot always the case that the first spanning variable is also the firstspanning variable in the apriori file. Even the number of variable canbe different. If not all variables of the safe file will be availablein the newly to be protected file, only the score for the total willbe used. This is often the case if the apriori file is generated for alinked tables problem. The separator to be used in the apriori file must be specified aswell; a comma is the default. Pressing the ‘Go’-button will generate the apriori file and the’ready’-button will bring you back to the main menu of \(\tau\)-Argus. 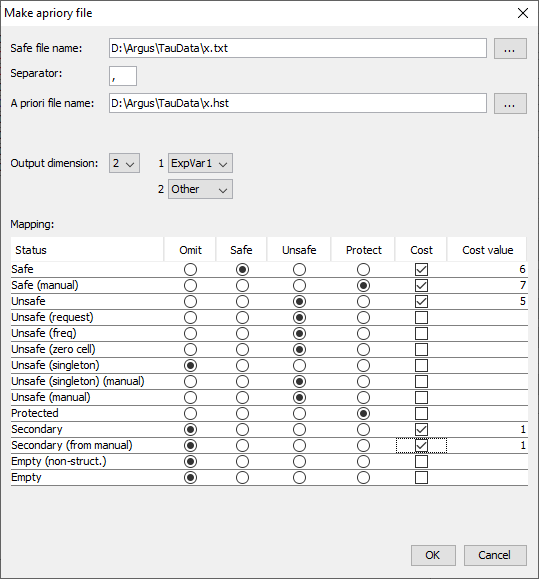
4.6.4 Output | Write Batch File
The commands used in interactive mode can be saved into a file forfuture use. \(\tau\)-Argus will write a batch file containing the commandsnecessary to achieve the current situation of the \(\tau\)-Argus run so far.For more information on the batch facility see section[4.3.3] For example the following shows the dominance rule (n=3, k= 75)applied to the Size by Region table with Var2 as the responsevariable. The threshold value = 5 with a safety range = 30%. Modularsecondary suppression was applied. The last line indicates that\(\tau\)-Argus will not stop after these commands but become an interactiveprogram. <OPENMICRODATA> "C:\Program Files\TauARGUS\data\tau_testW.asc" <OPENMETADATA> "C:\Program Files\TauARGUS\data\tau_testW.rda" <SPECIFYTABLE> "Size""Region"|"Var2"|""|"" <SAFETYRULE> NK(3,75)|NK(0,0)|FREQ(5,30)| <READMICRODATA> <SUPPRESS> MOD(1) <GOINTERACTIVE>
4.7 The Help menu
4.7.1 Help | Contents
This shows the contents page of the help file and from there makes thehelp available. This program has context-sensitive help. By pressingF1, the relevant page of the manual will be shown.
4.7.2 Help | News
Information on the latest developments is shown. Old friends can seehere which new extensions have been included in this version of\(\tau\)-Argus and information about bugs is shown here as well.
4.7.3 Help | Options
There are a number of options, which can be changed here. The coloursindicating the status of a cell can be altered. In order to make a hierarchical table more readable, the differentlevels of the hierarchy will be indicated with an increasing greybackground. If you like different colours, you can adapt this. For the modular solution the maximum computing time per subtable canbe specified. This could speed up the computations, but on the otherhand might give a less optimal solution. Also the name of the logfile (see section [5.8]) can bechanged here. By default it is Logbook.txt in the temp-directory. Finally the solver for the optimisation routines must be specified.The options are: cplex or Xpress or a free solver. \(\tau\)-Argus can workwith all three solvers. If the cplex optimisation routine is being used, the location of thelicence file can be specified here. For Xpress the name of the licencefile is prescribed and fixed (XPAUTH.XPR) The Xpress licence file hasto be stored in the \(\tau\)-Argus program directory. \(\tau\)-Argus will store the information of all these options in theregistry and will use it in future runs. It is advisable but notnecessary to open this window at the start of a \(\tau\)-Argus session toensure the correct solver has been chosen. 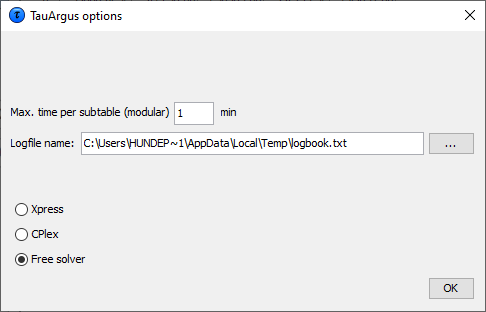
4.7.4 Help | About
Shows the about box.